Mit dem Regensburger Marathon-Cluster durch's Ziel
Erfahrungen
Hubert Feyrer, Mai 2001
Erfahrungen aus dem Regensburger Marathon-Cluster
Das Client Deployment dauerte etwas länger als erwartet.
Das installieren eines einzelnen Client-Rechners via g4u vom Master
Server dauerte ca. 30 Minuten, das anschliessende Kopieren des
ca. 650MB grossen Images auf den Rechner dauerte nochmal so lange. Das
anschliessende Deployment von diesem Room-Server dauerte relativ
lange, da jeweils 14 bzw. 11 Rechner um Bandbreite zum Room-Server
kämpften, und ausserdem alle Rechner der frei Räume auf einem
100MBit 3Com-Switch geschaltet waren. Insgesamt hätte hier eine auf
mehreren Switches basierende Struktur wohl etwas mehr Bandbreite für
die Room-Server schaffen können.
dumpmpeg läuft auf NetBSD und Linux, aber nicht auf Solaris bei
gleicher Hardware-Architektur. Die Cluster-Software wurde bei der
Firma R-KOM unter Linux getestet und lief dort ohne Probleme. Das auf
SDL und smpeg basierende dumpmpeg stürzte jedoch auf den
Solaris-Rechnern der FH Regensburg sporadisch ab. Debugging via gdb
zeigte dass hier wohl Speicherbereiche überschrieben wurden, da die
Abstürze in malloc(3) passierten. Es darf vermutet werden dass die
libc von NetBSD und Linux sich hier wohl etwas anders verhält als die
von Solaris, so dass evtl. überschriebene Speicherbereiche bei
letzterem eher zu Fehlern führen. Falls dies der Fall ist, so muss
die Stelle im SDL- bzw. smpeg-Quellcode gefunden und repariert werden,
was jedoch mehr Zeit benötigt als vorhanden war. Die Schuld ist hier
nicht bei Solaris direkt zu suchen, jedoch führt die Situation dazu
dass Solaris als Platform für die Cluster-Software nicht brauchbar
war, und somit 15 wertvolle Rechner ausgefallen sind. Mit etwas mehr
Vorlaufzeit und ausführlichen Tests in der endgültigen Zielumgebung
kann man solchen Effekten vorbeugen.
dumpmpeg lief länger als erwartet. Die 18-minütige Testsequenz
brauchte beim Tunen und Parametrisieren des Clusters ca. 60 Minuten
auf den Rechnern mit 1GHz. Parallelisieren des Einlesens der
Marathon-Filmdaten brachte hier erheblich Geschwindigkeitsvorteile,
jedoch bildeten sich gleichzeitig auch Engpässe durch gleichzeitige
Zugriffe auf gemeinsame Netzwerk- und Plattenressourcen. Insgesamt
dauerte das Einlesen und zerteilen der Quell-Sequenzen mit acht
Stunden ca. drei Stunden länger als ursprünglich geschätzt.
mpeg_encode kann nicht auf beliebig vielen Rechnern rechnen.
Eine Sequenz aus 156 Bildern kann nicht auf mehr als ca. 15 Rechnern
gerechnet werden, da sonst Fehler ausgegeben werden und das Programm
hängt. Um hier eine optimale Parallelisierung zu erreichen mussten
die aufrufenden Scripten, die die temporären Arbeitsverzeichnisse mit
Bildern füllen so angepasst werden, dass sie dies für
unterschiedliche Subcluster bewerkstelligen. Die Parameter-Dateien
für mpeg_encode mussten entsprechend angepasst werden, so dass
mehrere Subcluster mit Arbeit versorgt werden konnten.
mpeg_encode bricht gern nach der Ausgabe von "Wrote 160 frames"
ab. Ursache unbekannt, ein schneller Blick in den Quellcode
führte zu keiner Erleuchtung. Ein Abbrechen des Scripts führt hier zu
einem schnelleren Ergebnis. Es muss nur die Eingabedatei angepasst
werden, damit bereits berechnete Filme nicht nochmals berechnet
werden.
Diverse Bilder & Graphen
Die Plattenauslastung des NFS-Servers zeigt, dass mit dem Einlesen
(blau) der Sequenzen um 16:30 begonnen wurde, um ca. 1:15am waren alle
Sequenzen eingelesen. Die Schreibzugriffe (grün) zeigen die Zeiten
an, in denen zwischendurch bereits die Filme der zuerst durch Ziel
gegangenen Speedskater (Herren und Damen) berechnet wurden.
|
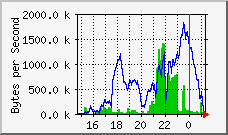
Die Betrachtung des Netzwerk-Verkehrs des NFS-Servers zeigt auch sehr
deutlich die Zeiten in denen die Sequenzen geschrieben wurden (blau),
und die Zeiten in denen die Berechnungen der Speedskater die
berechneten Bilddaten ausgelesen haben (grün).
|

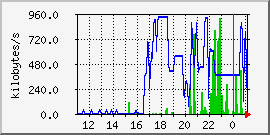
Netz-Traffic zwischen den Cluster-Rechnern und den Control Rechnern:
Während beim Deployment am Samstag zwischen 18h und 22h
hautpsächlich Daten aus dem Netz in dem die Cluster Control
und Deployment Rechner standen gelesen wurde (blau) wurde beim
eigentlichen Cluster-Lauf am Sonntag ab ca. 15h auch Daten produziert
(grün).
|
|
Image: (click to enlarge!)
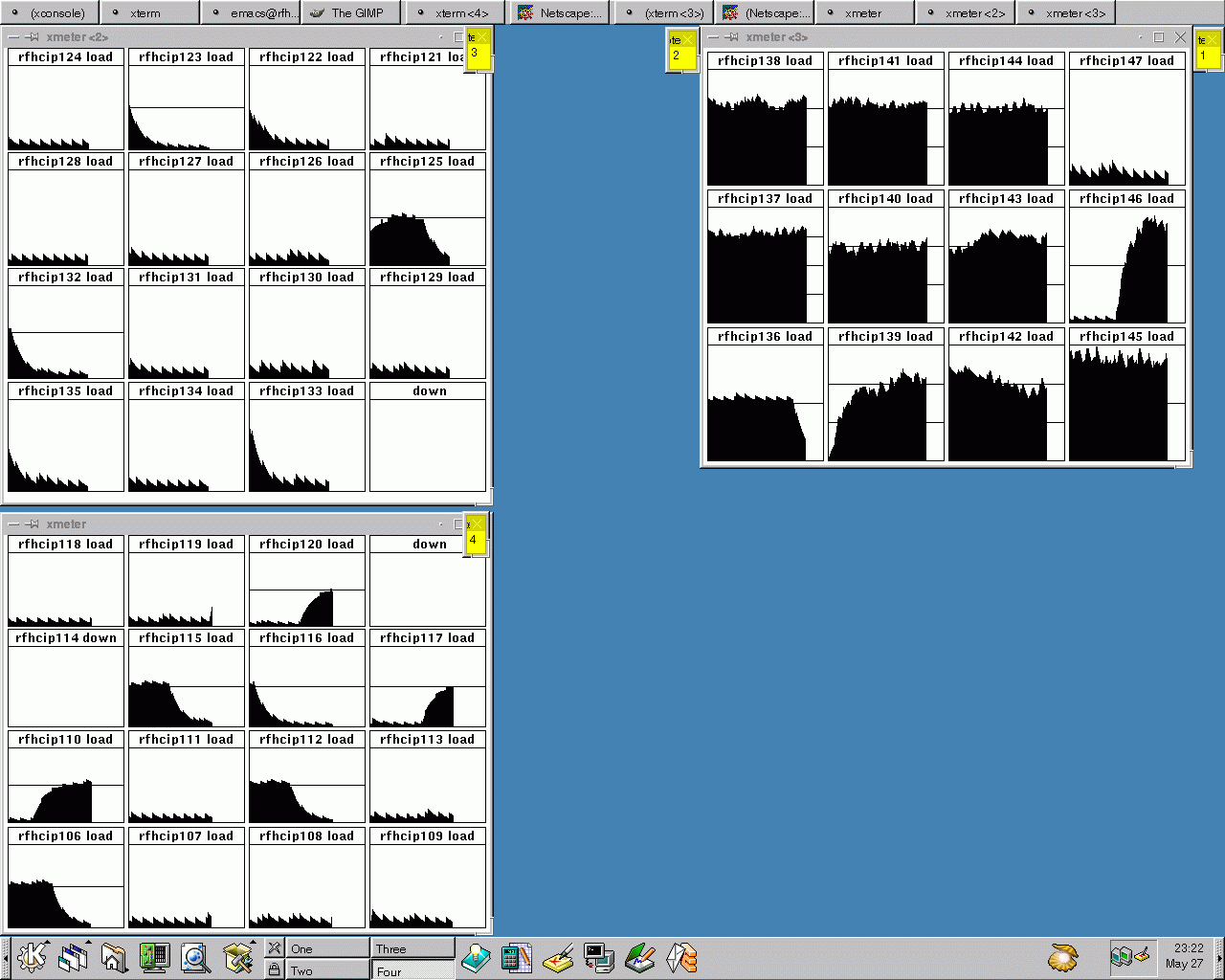
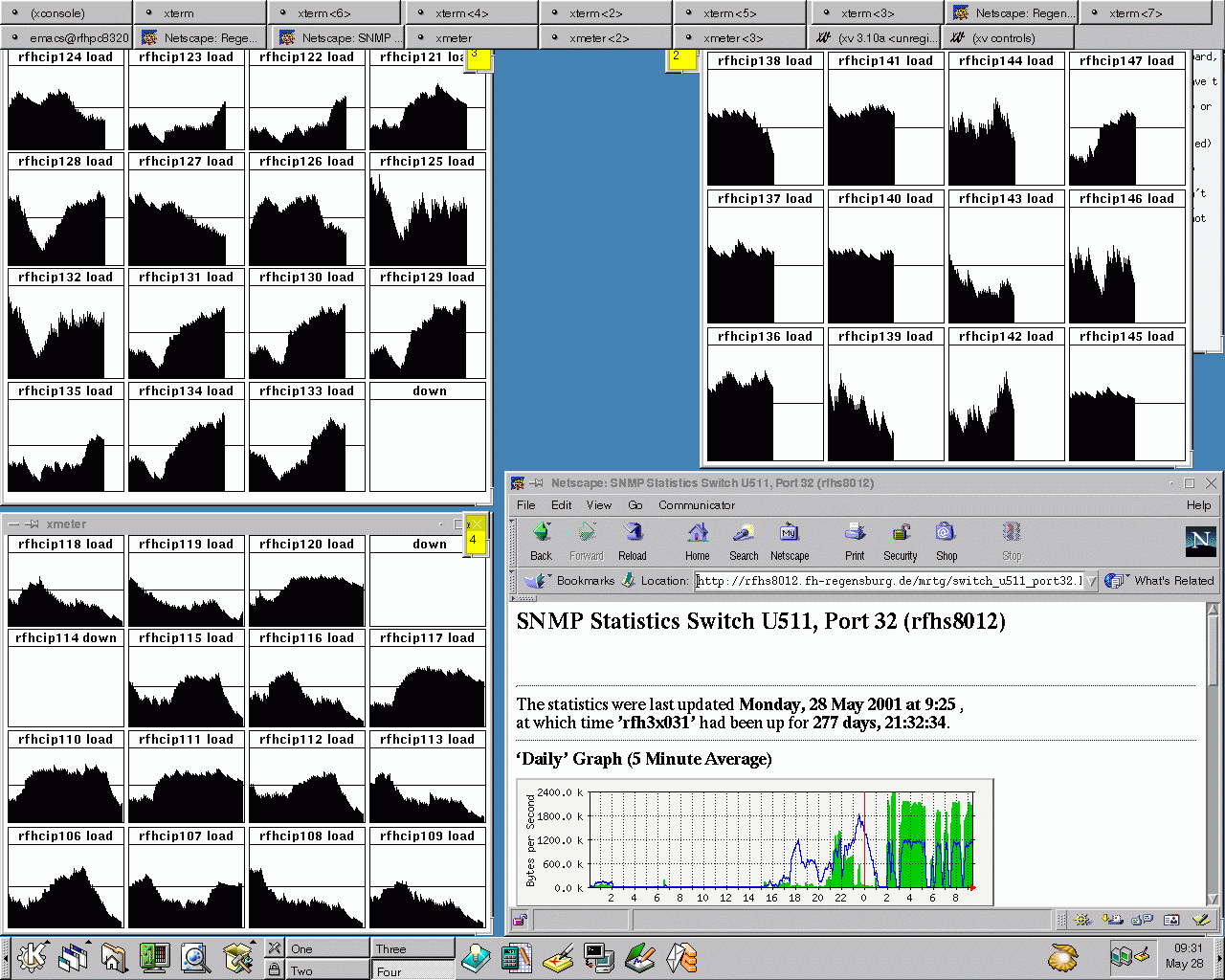
Sonntag, früher Nachmittag: während die Subcluster 3 und 4 (links, gelbe
Nummern) noch auf Daten warten zerlegen die GHz-Rechner in den
Subclustern 1 und 2 (rechts oben) die MPEG
Sequenzen in Einzelbilder.
|
|
Image: (click to enlarge!)
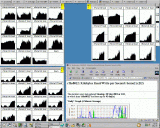
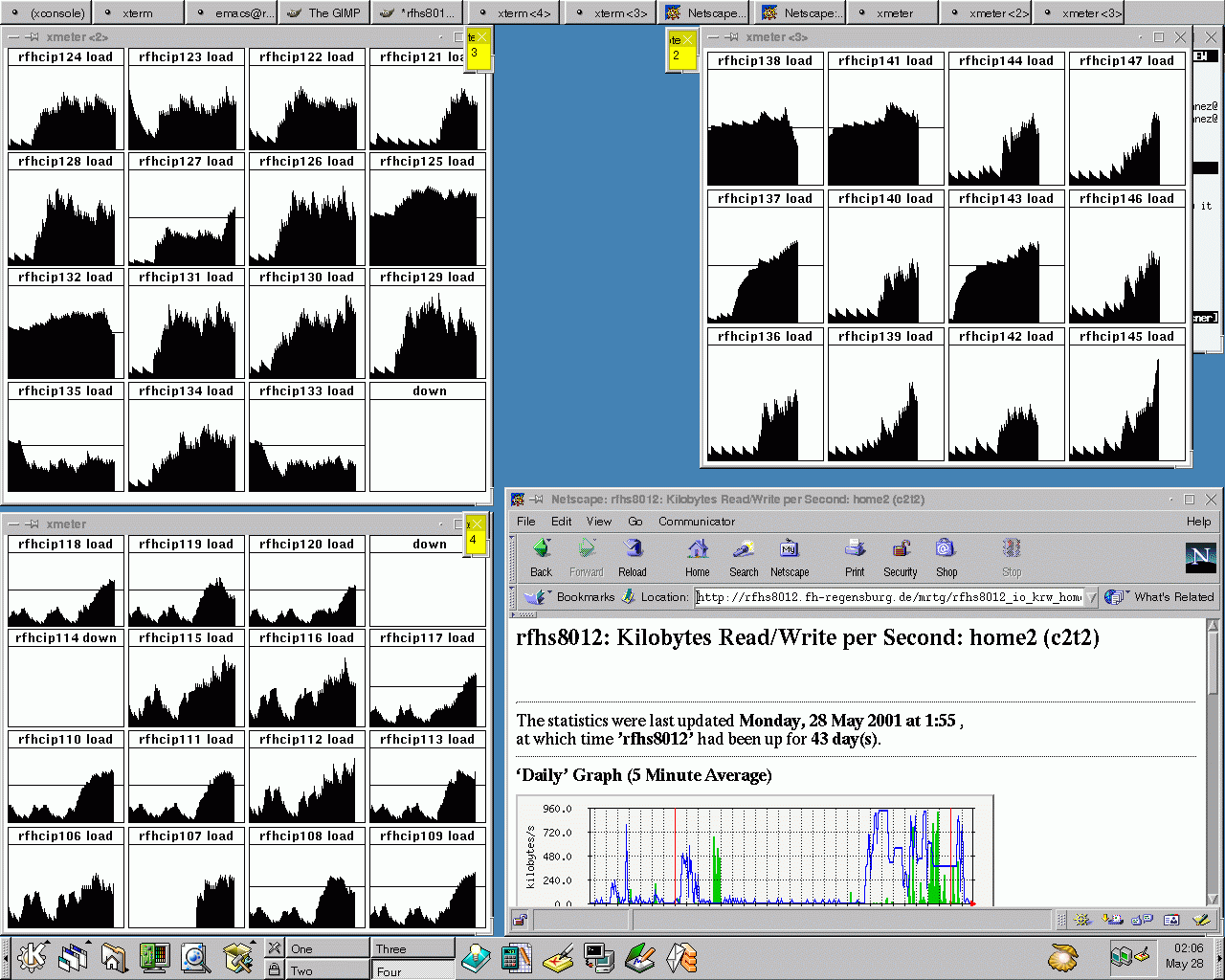
Montag 2am: Die letzte Sequenz ist zerlegt, ab nun kann der zweite Schritt
auf allen Rechnern und Subclustern parallel gestartet werden.
|
|
Image: (click to enlarge!)
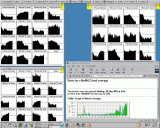
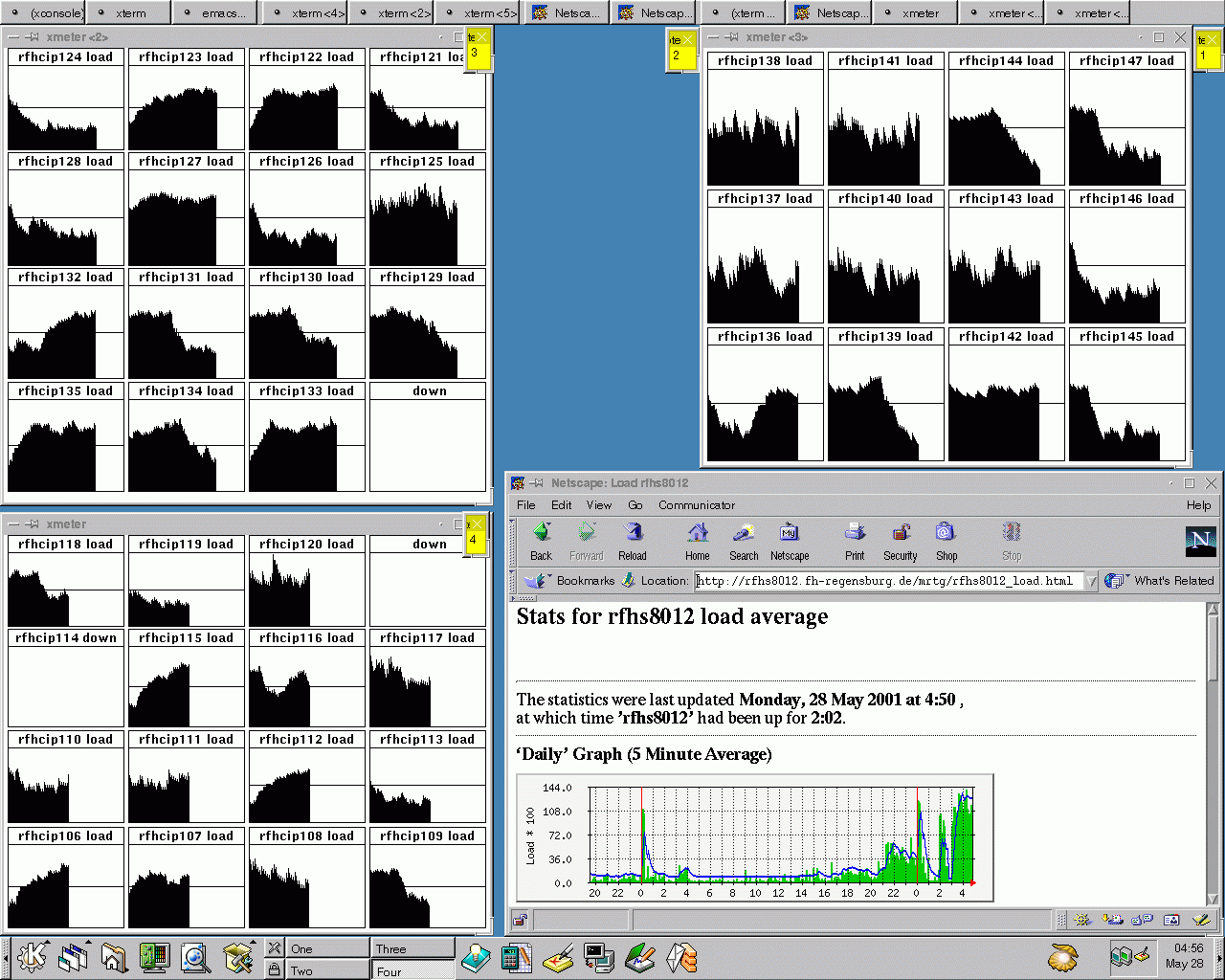
Montag 5am: Der NFS-Server (Solaris 2.6) muss um 3am wg. unerklärlicher
NFS/RPC/NIS-Probleme rebootet werden, anschliessend läuft der
Cluster unter Vollast. Noch 3 Stunden bis die Rechner wieder für
die Studenten zugänglich gemacht werden müssen!
|
|
Image: (click to enlarge!)
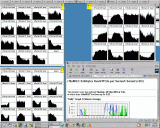
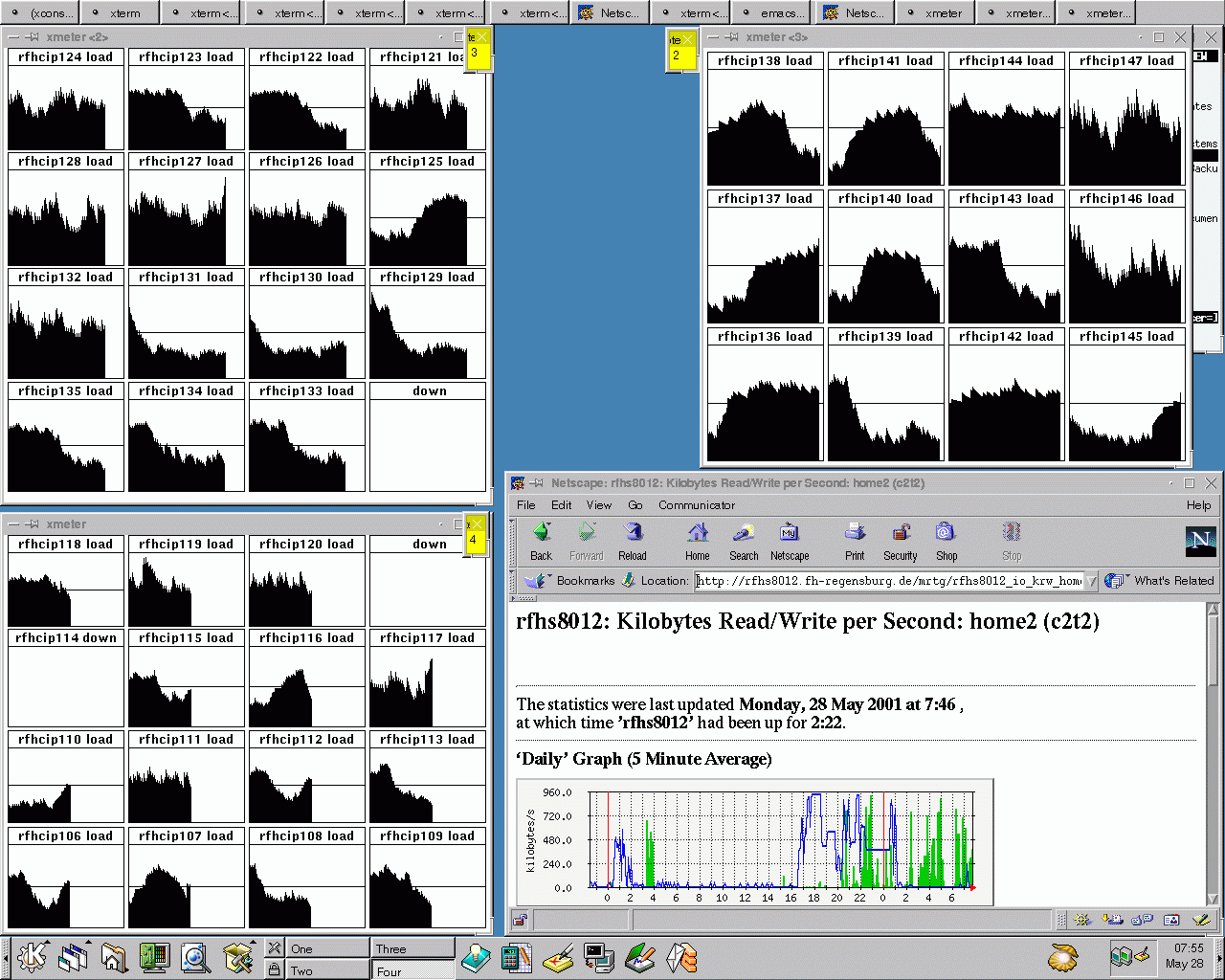
Montag, 5:30am: Eben gingen die gesamtem Scripten durch ein unbedachtes
"rm tempfiles *" (man beachte das zweite Leerzeichen!) verloren.
Eine am Samstag Abend zufällig gemachte Sicherheitskopie rettete
das Projekt.
Montag, 8am:
In den vergangenen Stunden haben mehrere Ausfälle die Arbeit bis zu einer
Stunde aufgehalten, Grund waren wiederum u.a. unerklärliche
Phänomene im Bereich NFS/Automounter. (Oder ggf. auch bootende
Netzwerk-Komponenten - wer weiss!).
Montag um 8am sind noch ca. 900+500 Halbmarathon- und ca. 500 Marathon-Filme
zu berechnen, aufgeteilt auf alle Subcluster. In den CIP-Pools sind bis
11:30 keine Lehrveranstaltungen so dass mehr Zeit bleibt.
|
|
Image: (click to enlarge!)
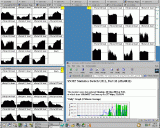
Montag, 9:35am: Nach diversen NFS-Hängern laufen die Clients momentan
wieder unter Vollast, das Ende ist in Sicht!
|
|
Montag, 10:40: Fertig! Alle Ergebnislisten sind abgearbeitet und
Stichproben der Zielbilder und -Videos zeigen gute Ergebnisse. Hier
von oben nach unten die Performance-Graphen des
Regensburger Marathon-Cluster Projektes:
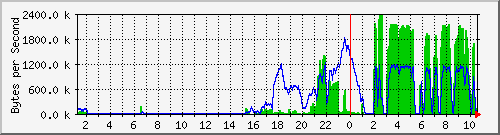
- Datenverkehr zwischen Control Rechnern und Cluster Rechnern:
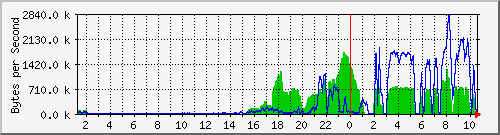
Gut erkennbar hier die zwei Schritte: schreiben der Bilder von
ca. 17h bis 1am, und gleichzeitiges Schreiben und Lesen von
ca. 2am bis zum Ende der Berechnung um 10:40.
- Die Plattenauslastung des NFS-Servers:
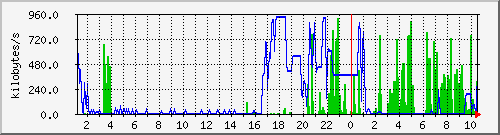
Hier ist sehr schön der Unterschied zwischen dem ersten und
zweiten Schritt zu sehen. Während beim zerlegen der MPEGs im
ersten Schritt nur Bilddaten geschrieben wurden (blau) wurden im
zweiten Schritt die Bilder zum Berechnen der Filme wieder gelesen
(gruen). Zwischen 21h und 23h wurden noch während Schritt 1 lief
bereits Schritt zwei für die Speedskater angestossen.
- Die Systemlast (Load) des NFS-Servers:
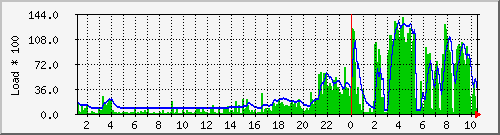
Schritt eins (bis ca. 2am) verlangte dem NFS-Server nicht
allzuviel Arbeit ab, die hohe Last um Mitternacht geht auf
diverse System-Jobs zurück. Ab 2am erhöhte Last durch
gleichzeitiges Lesen und Schreiben im 2. Berechnungsschritt des
Clusters. Auffallend hier mehrere Unterbrechungen um 3am, 5:30am,
7:30am und 8:30am.
- Die CPU-Auslastung des NFS-Servers:
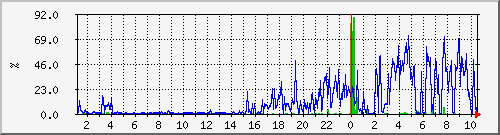
- Die Netzwerk-Auslastung des NFS-Servers:
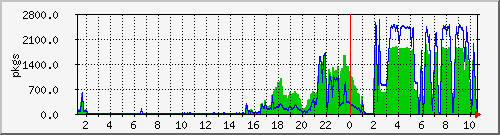
- Datenverkehr des NFS-Servers am Switch gemessen:
|
>>> Fakten
Copyright (c) 2001 Hubert Feyrer