This article is all from Gregory, I'm only providing
the webspace! - Hubert
Benchmark Comparison of NetBSD 2.0 and FreeBSD 5.3
Gregory McGarry
g.mcgarry@ieee.org
Abstract:
With the recent releases of NetBSD 2.0 and FreeBSD 5.3 operating
system, many new and exciting features have been implemented. Both
criticism and commendation on performance, reliability and scalability
have been directed towards these releases.
This paper presents a suite of benchmarks and results for comparing
the performance of these operating systems. The benchmarks target
core operating system functionality, server scalability and thread
implementation. These benchmarks are useful server-based criteria for
demanding applications such as loaded webservers, databases, and
voice-over-IP (VoIP) media relays. The results indicate that NetBSD
has surpassed FreeBSD in performance on nearly every benchmark and is
poised to grab the title of the best operating system for the server
environment.
The FreeBSD and NetBSD operating systems are complete Unix-like
operating systems sharing a common BSD Unix lineage. Although both
operating systems share a similar development style and source code,
each project has traditionally had very different objectives. Ask
almost anybody familiar with at least one of the projects as to which
is the better operating system, and the reply will usually recommend
FreeBSD for servers and desktop systems, and NetBSD for obscure
hardware. FreeBSD has historically been clean, fast, reliable and
scalable and NetBSD is known to support fifty-four different system
architectures.
However, in recent years, the traditional arguments for choosing one
operating system over the other has waned. FreeBSD now supports six
popular system architectures and NetBSD recently set Internet
land-speed records.
Long criticized for their slow release schedules, the NetBSD Project
announced in December 2004 the release of NetBSD 2.0. NetBSD 2.0
represents more than two years of development over the last major
release, and includes significant developments in the areas of
symmetrical multiprocessing (SMP) and high-performance POSIX threads.
Despite the long delay in delivery, the release has been warmly
accepted by the industry.
One month earlier, the FreeBSD Project announced the release of
FreeBSD 5.3; the first ``stable'' release of the FreeBSD-5 development
branch. In contrast with NetBSD 2.0, FreeBSD 5.3 has received a
barrage of criticism of its performance, scalability and
reliability[1]. Indeed, the FreeBSD-5 branch has been
plagued with problems from the very beginning. These problems have
primarily centered round an ambitious new scheduler, a complicated
threading model and fine-grained SMP architecture. All these problems
have left most FreeBSD installations stuck with the aging FreeBSD-4
branch.
With simultaneous releases of NetBSD 2.0 and FreeBSD 5.3, the industry
is now returning to the original questions: Which is the
better operating system? For servers? For embedded? However, this
time, the traditional response is not being used.
In the remainder of this paper, benchmark comparisons are
presented to compare the underlying performance of the operating
systems.
The responsibility of the operating system is to manage resources and
provide services to applications to access these resources. In
demanding environments, significant load will be placed on these
resources and the performance of the operating systems under this load
is of specific interest. Some of the benchmarks measure the
efficiency of the operating system for frequent, time-sensitive
functionality. Other benchmarks seek to identify the scalability of
the operating system during network operations[2].
Three categories of benchmarks have been used. The first category
measures core operating system functionality:
- system-call overhead
- context-switch time
- process creation time
- process termination time
- program load time
The second category measures the scalability of the operating system
under application and network load:
- process creation time for increasing load
- process termination time for increasing load
- memory-mapped file setup time
- memory-mapped file access time
- socket creation time
- latency to bind an address to a socket
The last category measures the overhead of the native threading model:
- thread creation time for increasing load
- thread lifecycle overhead
- uncontested mutex access overhead
- condition variable access time
- thread context-switch time
The benchmark hardware was an Asus P4-800SE mainboard, Intel 3GHz P4
processor (1MB L2 cache) and 1GB RAM. Both NetBSD 2.0 and FreeBSD 5.3
default installations were used for the benchmarks. No custom kernels
were used and no kernel tuning beyond the default installation was
performed.
This section presents the benchmark results for the three benchmark
categories.
The primary resource managed by the operating system is the CPU.
Management of process access to the CPU is managed by the kernel
scheduler using priority-based, time-slice allocation. On a
single-CPU machine, the appearance of parallelism is achieved by
quickly switching between process contexts. There is CPU overhead
associated with this operation. It is important for the operating
system to minimize this overhead, particularly during high system
load.
Through general use of the operating system, many processes will be
created, executed and terminated. This lifecycle is an integral part
of the operating system and the efficiency of the operating system to
perform it is important. All processes in BSD are created using the
traditional fork/exec Unix process-creation model.
This model was part of the original Unix design, and is still
implemented in virtually every version of Unix available today.
The fork and exec operations are system calls. A
system call is the interface between the user-level application and
the kernel. The fork system call creates a new process. The
newly created process gets a unique process identification and is a
child of the process that has called fork. The calling process is the
parent. The exec system call overlays the process address
space with data from an executable file. A process is terminated with
the _exit system call. It is generally invoked indirectly
using exit() in the standard C library.
The benchmarks developed in this section measure these important
operating system functionality. The results are shown in
table 1.
Table 1:
Performance comparison of core operating system functionality.
benchmark (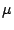 s) s) |
NetBSD |
FreeBSD |
|---|
|
system-call overhead |
0.368 |
0.393 |
|
context-switch |
2.64 |
3.45 |
|
process creation (dynamic) |
146 |
168 |
|
process creation (static) |
63 |
80 |
|
process termination (dynamic) |
43 |
64 |
|
process termination (static) |
32 |
36 |
|
program load (dynamic) |
463 |
1424 |
|
program load (static) |
96 |
266 |
The system-call overhead benchmark measures the time for the operating
system to switch from unprivileged user mode to privileged kernel mode
and returning to unprivileged user mode. This metric is performed by
measuring the time to execute the getpid system call, which
is the simplest system call available in the operating system.
The results in Table 1 shows that NetBSD 2.0 marginally
out-performs FreeBSD 5.3.
The context-switch time benchmark measures the time for the operating
system to switch from the execution context of a process to another.
A context switch requires the kernel to save the address space and CPU
registers of the current process and load them for the next process.
The kernel must also manage coherency of the CPU caches. This metric
is performed by creating two processes connected with a bi-directional
pipe. A one-byte token is passed alternately between the two
processes, causing a context switch to each process to services access
to the pipe.
The results in Table 1 shows that NetBSD 2.0 marginally
outperforms FreeBSD 5.3.
The process creation time measures the execution time of the
fork system call. There are several optimizations which the
operating system will perform to optimize the creation of the new
processes. During a fork system call, the kernel will share
the parent address space read-only with the child. A new
process identification is allocated to the child process in addition
to other data structures used for process-specific accounting. If the
child subsequently writes to the address space it shares with its
parent, a copy-on-write of the altered page is made into the
child address space. However, if the child process terminates
immediately, or invokes the exec system call, the
address-space is returned unchanged to the parent without performing a
complete address-space copy. This metric is performed by creating a
pipe between the parent and child processes. The parent measures the
time for the child process to be created when it receives a one-byte
token sent on the pipe from the child process.
Process termination time is equally important. The address space must
be reclaimed in addition to other data structures used for
process-specific accounting. This metric is performed by the parent
sending the child process a SIGTERM signal and invoking the
wait4 system call to wait for child termination.
The execution times of the fork and exec system
calls are also sensitive to the address space layout of the process.
In particular, dynamic-linked executables using relocatable objects
produce sparse address spaces in comparison to static-linked
executables. Memory management is impacted by the sparse address
space. The benchmarks have been developed to compare the metrics for
dynamic-linked and static-linked executables.
The results in Table 1 indicate that NetBSD 2.0
marginally outperforms FreeBSD 5.3. The performance difference for
dynamic-linked executables is particularly noticeable.
Scalability refers to the ability of the operating system to perform
operations during increased demand for resources. Scalability is
particularly important on systems with high application and network
load. For example, a system running a demanding network or database
server may require significant network sockets and fork many worker
child processes. The performance of the operating system as the
system load increases is an important criteria for system architecture.
Continuing from the previous section, the first benchmark considers
the process creation and termination times as the number of system
processes increases. This benchmark measures the architectural design
of the scheduler. Results for process creation and termination times
for dynamic-linked executables are presented in
Figure 1 and
Figure 2 respectively. The results for
static-linked executables are shown in
Figure 3 and
Figure 4 respectively.
Figure 1:
Process creation times for increasing number of system
processes with a dynamic-linked executable.
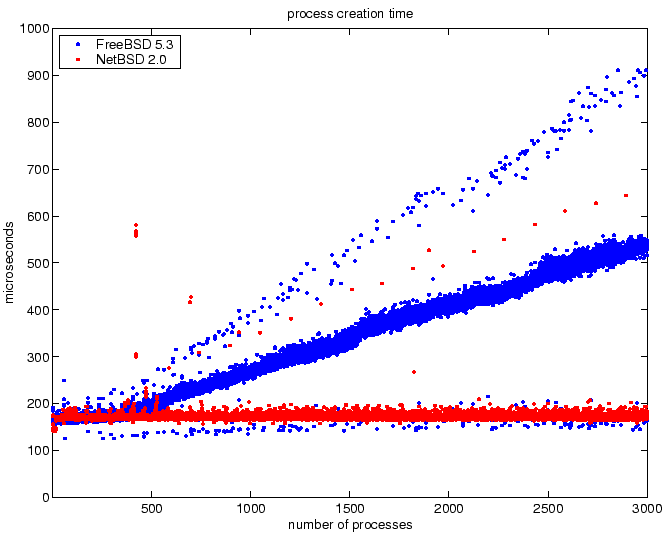 |
Figure 2:
Process termination times for increasing number of system
processes with a dynamic-linked executable.
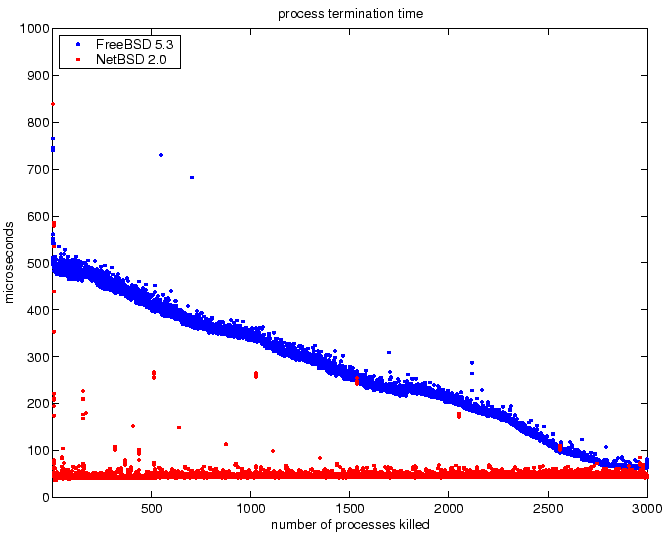 |
Figure 3:
Process creation times for increasing number
of system processes with a static-linked executable.
 |
Figure 4:
Process termination times for increasing number
of system processes with a static-linked executable.
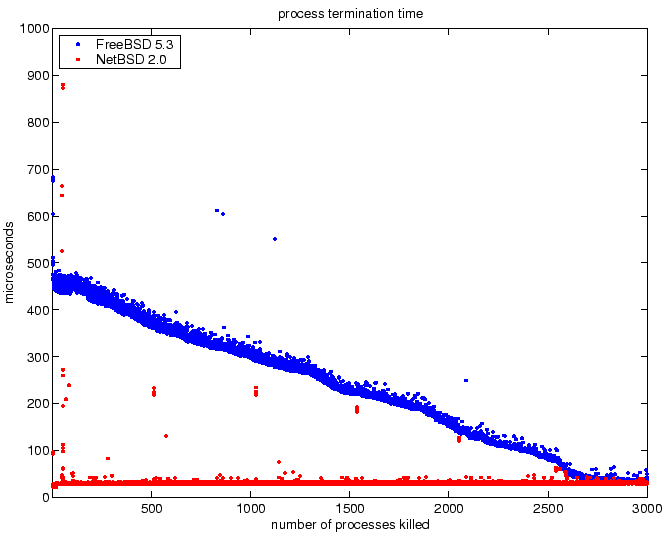 |
The plot for process termination may be difficult to interpret. The
benchmarks starts with 3000 system process and measures the time to
terminate each process as the number of system processes is reduced.
These results indicate the NetBSD kernel has very efficient data
structures for managing system processes to permit constant
access-time to allocate new process resources, such as a process
identification, and to locate the process for termination. For this
benchmark, NetBSD has excellent scalability, since the time to perform
process creation and termination is not affected by the number of
system processes.
The FreeBSD kernel has an access time which scales linearly with the
number of system processes. There are also many occasions when the
access-time is very fast, resembling a constant access time. An
explanation for this result may be that an optimization within the
FreeBSD kernel is performed to arrange access to resources
appropriately to minimize the access time. However, there are also
many occasions when the access-time is half as fast as the nominal
value. Perhaps the optimization does not work well for every
workload?
The mechanism for mapping shared libraries into a process address
space is the mmap system call. This system call permits a
process to map data of arbitrary size from a file into its address
space. The mechanism is also used by some databases, web servers and
proxy servers to map files into memory rather than reading the file
contents into the system buffer cache.
To support the mmap system call, the operating system must
maintain data structures for system-wide memory accounting and data
structures for the process-specific file-mapped data. A benchmark is
used to measure the performance of these data
structures[2].
The benchmark maps many 4KB windows from a 200MB file, each offset by
4KB from the previous window. A common optimization for the operating
system is to ``lazily'' map the data into the address-space on the
first access, rather than mapping it at the time of the mmap
system call. The benchmark measures the time to invoke the initial
mmap system call, shown in Figure 5, and
the time to access the first byte of the mapped window, shown in
Figure 6.
Figure 5:
Comparison of times to map a 4KB window from a file into
process address space for increasing number of mappings.
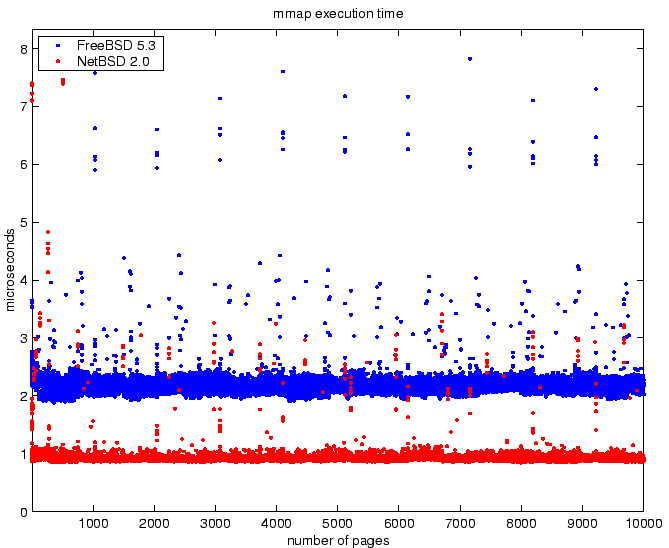 |
Figure 6:
Comparison of access times for a 4KB memory-mapped window for
increasing number of mappings.
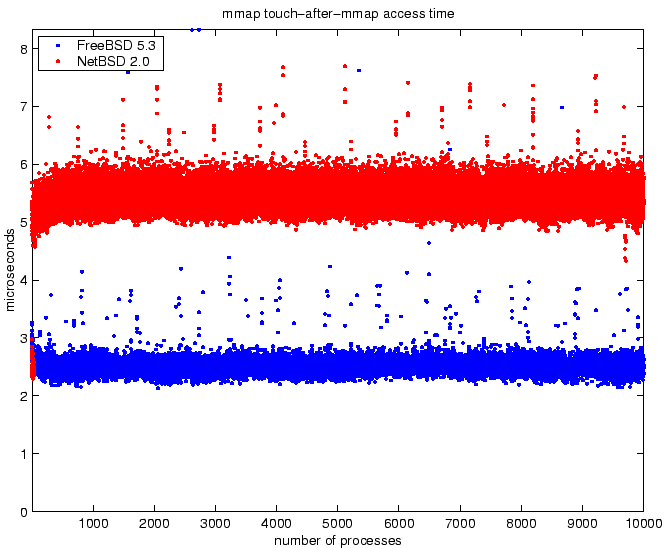 |
The results show excellent scalability for both NetBSD and FreeBSD.
Both operating systems permit constant access-time for mapped-memory
files with increasing load. FreeBSD has the peculiar behavior that
the memory mapping time is clearly distributed around two values.
For the initial mmap system call, NetBSD has 113% improved
performance over FreeBSD. For accessing the memory-mapped file,
FreeBSD has 116% improved performance over NetBSD. For frequent
mapping operations which are not accessed, NetBSD will show better
performance. However, for the general case with infrequent mapping
operations and frequent accesses, FreeBSD will show better
performance. The total of both benchmarks indicate that for a single
mapping and subsequent access, FreeBSD shows a 38% performance
improvement over NetBSD.
Sockets are the basis for communication in BSD operating systems.
They can be used for inter-process communication and network
communication.
A socket is created using the socket system call. The system
call returns a file descriptor which permits the traditional file
operations to be used for communication. Benchmarking the
socket system call measures the time the kernel takes to
allocate the necessary data structures and the time to find the lowest
unused file descriptor for the process. This latter task becomes more
difficult for a large number of open file descriptors and affects
scalability.
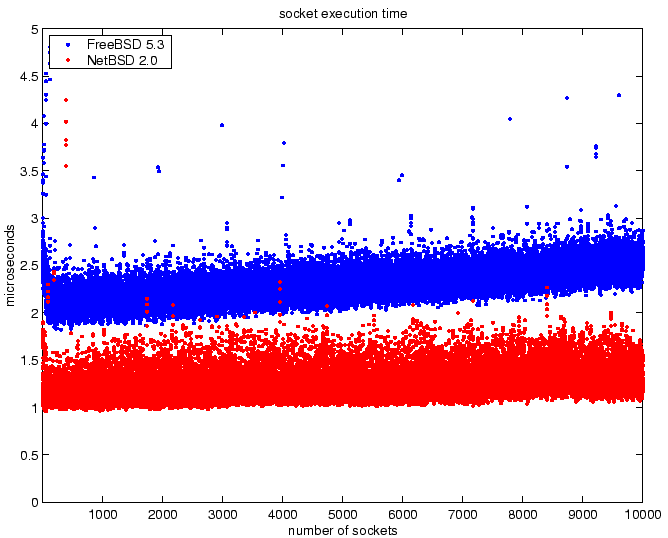
The results for socket creation for increasing number of allocated
sockets are shown in Figure 7. The results show that
socket creation time for both NetBSD and FreeBSD increases linearly
with the number of allocated sockets. The rate increases slightly
more for FreeBSD than NetBSD, and NetBSD produces faster allocation
times. Neither NetBSD nor FreeBSD shows scalability problems.
Figure 7:
Socket creation time for increasing number of allocated
sockets.
 |
When a socket is created with the socket system call, it
exists for an address family, but does not have an accessible address
associated with it. The bind system call assigns an address
to the socket.
This benchmark measures the time for the kernel to allocate the
necessary resources to assign an unused TCP port to the socket. The
benchmark is not important for scalable web servers, however it is
important for voice-over-IP (VoIP) proxy servers and media relays.
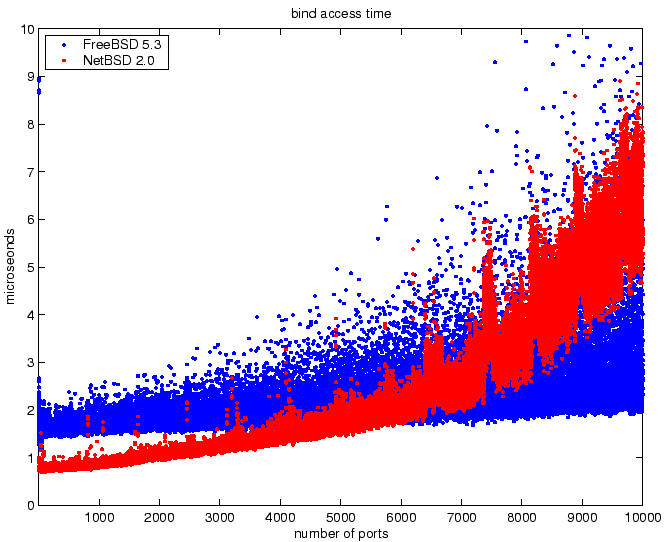
The results for the socket binding benchmark are shown in
Figure 8. The results show that both NetBSD and FreeBSD
scale linearly with the number of bound sockets. For a small number
of bound sockets, NetBSD has the better latency than FreeBSD.
However, the linear gradient for NetBSD is significantly worse than
FreeBSD. This result indicates the FreeBSD scales better for binding
addresses to sockets.
Figure 8:
Socket bind time for increasing number of bound sockets.
 |
NetBSD 2.0 is the first release to support the new threads system
based on scheduler activations[3]. It includes the
implementation of a POSIX-compliant threads library that uses the
scheduler activations interface. The library includes many
optimizations to attain impressive performance[4].
The importance of the process lifecycle was previously mentioned; from
process creation, through process scheduling, to process termination.
Similarly, threads go through the same lifecycle and the performance
of the thread implementation to manage this lifecycle is important.
For many applications, the demands on the thread implementation are
more onerous than the demands on the kernel scheduler.
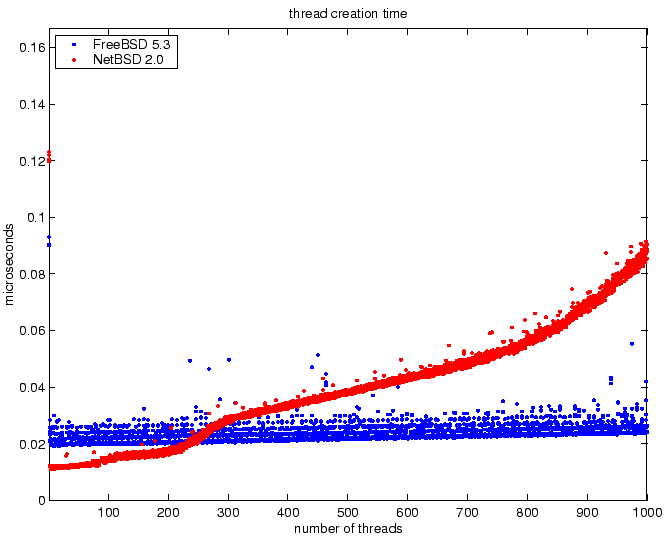
The times to create a new thread for increasing number of threads is
shown in Figure 9. This result shows that the
FreeBSD thread implementation creates new threads with constant time.
This result indicates that FreeBSD has good scalability. The creation
of the first thread in NetBSD has significant latency. This result
occurs because the NetBSD threads implementation defers the
initialization of the threads library to the creation of the first
thread rather than doing the initialization when the threads library
is loaded.
For less than 250 threads, the time to create a thread is better in
NetBSD than FreeBSD. For more than 250 threads, the thread creation
time increases as the number of threads increases. Of particular
concern, the relationship is not linear for the number of threads.
Although one thousand threads is ample for most multi-threaded
applications, the poor scalability may be a problem for some
applications.
Figure 9:
Thread creation time.
 |
Another benchmark is to measure the complete lifecycle of a thread, by
creating, joining and terminating a thread. The processing time is
presented in Table 2.
Threaded applications also make extensive use of mutexes and condition
variables to serialize access to shared data. Mutexes are commonly
used and in many cases their access is uncontested. A benchmark which
measures the time to acquire an uncontested mutex is shown in
Table 2. Another benchmark measures the time for a
thread waiting on a condition variable to respond. The benchmark uses
ten worker threads and a master thread. The worker threads
conditionally wait on a variable that the master thread sets. When
the variable is set, a signal is broadcast to wake any worker thread.
The woken worker thread clears the condition variable, signals the
master to set the condition variable, and immediately waits on the
condition variable. The results of the benchmark are shown in
Table 2.
Table 2:
Benchmark comparisons for thread operations.
|
benchmark (s) |
NetBSD |
FreeBSD |
|---|
|
thread lifecycle |
2.35 |
4.33 |
|
uncontested mutex |
0.0372 |
0.282 |
|
condition variable wakeup |
1.21 |
4.86 |
The results of these benchmarks for the basic POSIX thread primitives
clearly shows that the NetBSD thread implementation contains many
impressive optimizations. The threads implementation framework based
on scheduler activations permits low-overhead, efficient allocation
of CPU resources to the threads[3]. The effect of
restartable atomic sequences for the mutex implementation is also
significant[4].
The reasons for optimizing process context switches equally applies
for optimizing thread context switches. The ``ping-pong'' benchmark
measures thread context-switch time for different number of threads.
The benchmark was devised to test the quality of Solaris threads
library implementations[5].
The benchmark consists of a pair of threads in lock-step
synchronization, resembling the game of ``ping-pong''. For each
iteration, each thread is alternately blocked and unblocked by the
other. The game continues until a specified number of iterations has
been completed by each thread. The game also permits the playing of
multiple concurrent games within a single process, testing the
performance when the thread scheduler is under load.
Three experiments are considered:
- one game, 2 players, 1000000 iterations, default stack size
- four games, 8 players, 1000000 iterations, default stack size
- 500 games, 1000 players, 100 iterations, 32KB stack size
The number of mutex operations and the number of context switches
should be twice the number of iterations. The times to create the
threads and play the game are shown in Table 3.
Table 3:
Result of the ``ping-pong'' benchmark.
|
benchmark (s) |
NetBSD |
FreeBSD |
|---|
|
1 |
thread creation time |
374 |
215 |
|
|
game completion time |
954 660 |
3 139 256 |
|
2 |
thread creation time |
517 |
446 |
|
|
game completion time |
5 049 811 |
13 062 477 |
|
3 |
thread creation time |
23 535 |
41 154 |
|
|
game completion time |
140 551 |
275 145 |
Experiment 1 shows that the creation time for the two processes
favors the FreeBSD implementation over the NetBSD implementation.
This result agrees with the results shown in
Figure 9. The creation of the first thread
incurs a significant penalty on NetBSD. However, the time to complete
the game is significantly higher for FreeBSD over NetBSD. This is due
to increased latency in the thread lifecycle and the much longer mutex
acquire time for FreeBSD over NetBSD.
Experiment 2 shows similar results to Experiment 1. For four threads,
the overhead of the initial thread creation in NetBSD is not as
significant. The improved processing performance of NetBSD over
FreeBSD is similar for both experiments.
The default thread stack size in NetBSD is 2MB. To create a large
number of threads, the stack size can be reduced using the
PTHREAD_STACKSIZE environment variable. In experiment 3, the stack
size is reduced to 32KB. For 500 threads, the faster thread creation
implementation on NetBSD outperforms the FreeBSD implementation. For
500 simultaneous games, the margin of improvement of NetBSD over
FreeBSD is noticeable, but less significant as the other experiments.
This paper has presented a suite of benchmarks and results for
comparing the performance of NetBSD 2.0 and FreeBSD 5.3 in the areas
of core operating system functionality, network scalability and thread
performance.
The results clearly indicate that recent architectural decisions in
the NetBSD operating system have closed the performance gap between
NetBSD and FreeBSD. In fact, NetBSD has surpassed FreeBSD in
performance in the areas investigated in this paper. Significant
performance improvements are obviously visible in the thread
implementation.
Microbenchmarks are not always the best indicators to make judgments
on the overall performance of one operating system over another.
However, they are useful to infer an understanding of the
architectural decisions that go into building an operating system.
For many applications, the results presented in the paper may never
affect performance. For others, the scalability of the operating
system may simply not permit the application to run suitably.
There are many other interesting developments in NetBSD 2.0 and
FreeBSD 5.3 that deserve to be compared. Although NetBSD 2.0 has
outperformed FreeBSD 5.3 in most of the benchmarks presented here,
FreeBSD 5.3 has made significant developments with its symmetric
multiprocessor (SMP) architecture, particularly in the area of
scalability with fine-grained locking. NetBSD 2.0 continues to use a
single lock to serialize access to kernel mode. Additionally, the
performance of the thread implementation on multiprocessor systems,
where thread concurrency can be achieved, would be worth
investigating. Benchmarks for these areas are the objective of future
research.
The scalability benchmarks were supplied by F. von
Leitner[2]. The threads benchmarks were provided by the
Gelato project at the University of New South Wales, Australia
(http://www.gelato.unsw.edu.au/IA64wiki/NPTLbenchmarks). The
``ping-pong'' benchmark was provided by Sun
Microsystems[5]. Source code for the other benchmarks can
be found at
ftp://ftp.netbsd.org/pub/NetBSD/misc/gmcgarry/bench/.
-
- 1
-
J. Matzan, ``FreeBSD 5.3 is ``stable'' but not production-ready'', http://www.newsforge.com/article.pl?sid=04/12/14/1518217, December 2004.
- 2
-
F. von Leitner, ``Benchmarking BSD and Linux'', http://bulk.fefe.de/scalability/, October 2003.
- 3
-
N. Williams, ``An implemenation of scheuler activations on the
NetBSD operating system'', In Proceedings of the 2002 Usenix
Annual Technical Conference, 2002.
- 4
-
G. McGarry, ``An implementation of Restartable Atomic Sequences on the NetBSD operating system'' USENIX Annual Technical Conference, June 2003.
- 5
-
Sun Microsystems, ``Multithreading in the Solaris Operating
Environment'', A Technical White Paper, 2002
2005-01-03
Access count:
104358