|
[20211230]
|
Back from the dead
I had to move servers a few months back,
and in the process something went south with
this blog. I've changed a few things, and
the blog is alive now again.
As a matter of fact, I have little time for NetBSD
these days, so don't expect many new articles.
Just take this as a sign of life. :-)
Of course if you think I should add some entry
on something here, drop me an email and who knows - maybe
I can get things rolling again here?
[Tags: blog, hubertf]
|
|
[20180317]
|
The adventure of rebuilding g4u from source
I was asked by a long-time
g4u user on help with rebuilding
g4u from sources. After pointing at the
instructions on the homepage,
we figured out that a few lose odds and ends didin't match.
After bouncing some advices back and forth, I ventured into the
frabjous joy of starting a rebuild from scratch, and quick enough
ran into some problems, too.
Usually I cross-compile g4u from Mac OS X, but for the fun of it
I did it on NetBSD (7.0-stable branch, amd64 architecture in VMware Fusion)
this time. After waiting forever on the CVS checkout, I found that
empty directories were not removed - that's what you get if you have -P in your ~/.cvsrc file.
I already had the hint that the "g4u-build" script needed a change to have
"G4U_BUILD_KERNEL=true".
From there, things went almost smooth: building indicated a few
files that popped up "variable may be used uninitialized" errors,
and which -- thanks to -Werror -- bombed out the build. Fixing
was easy, and I have no idea why that built for me on the release.
I have sent
a patch with the required changes
to the g4u-help mailing list. (After fixing that I apparently
got unsubscribed from my own support mailing list - thank you
very much, Sourceforge ;)).
After those little hassles, the build worked fine, and gave me
the floppy disk and ISO images that I expected:
> ls -l `pwd`/g4u*fs
> -rw-r--r-- 2 feyrer staff 1474560 Mar 17 19:27 /home/feyrer/work/NetBSD/cvs/src-g4u.v3-deOliviera/src/distrib/i386/g4u/g4u1.fs
> -rw-r--r-- 2 feyrer staff 1474560 Mar 17 19:27 /home/feyrer/work/NetBSD/cvs/src-g4u.v3-deOliviera/src/distrib/i386/g4u/g4u2.fs
> -rw-r--r-- 2 feyrer staff 1474560 Mar 17 19:27 /home/feyrer/work/NetBSD/cvs/src-g4u.v3-deOliviera/src/distrib/i386/g4u/g4u3.fs
> -rw-r--r-- 2 feyrer staff 1474560 Mar 17 19:27 /home/feyrer/work/NetBSD/cvs/src-g4u.v3-deOliviera/src/distrib/i386/g4u/g4u4.fs
> ls -l `pwd`/g4u.iso
> -rw-r--r-- 2 feyrer staff 6567936 Mar 17 19:27 /home/feyrer/work/NetBSD/cvs/src-g4u.v3-deOliviera/src/distrib/i386/g4u/g4u.iso
> ls -l `pwd`/g4u-kernel.gz
> -rw-r?r-- 1 feyrer staff 6035680 Mar 17 19:27 /home/feyrer/work/NetBSD/cvs/src-g4u.v3-deOliviera/src/distrib/i386/g4u/g4u-kernel.gz
Next steps are to confirm the above changes as working
from my faithful tester, and then look into how to merge this
into the
build instructions .
[Tags: g4u]
|
|
[20180119]
|
No more Google ads
|
I've had Google Adsense advertising for quite a while on my blog,
the g4u homepage and various other pages.
In the start a little bit of money came in.
This has all dried up long since, and in light of
privacy regulations like the EU GDPR I've decided to
not give away my users' data to Google any longer.
So, there it is - my blog and other pages are free for your use now,
and you are no longer the product being sold. Enjoy! :-)
(If you find any remaining advertisement, drop me a line!)
|
 |
[Tags: adsense, google]
|
|
[20180104]
|
NetBSD 7.1.1 released
On December 22nd, NetBSD 7.1.1 was released as premature
christmas present, see
the release annoucement.
NetBSD 7.1.1 is the first update with security and critical
fixes for the NetBSD 7.1 branch. Those include a number of
fixes for security advisories, kernel and userland.
[Tags: Releases]
|
|
[20180104]
|
New year, new security advisories!
So things have become a bit silent here, which is due
to reallife - my apologies. Still, I'd like to wish
everyone following this here a Happy New Year 2018!
And with this, a few new security advisories have
been published:
[Tags: Security]
|
|
[20180104]
|
34C3 talk: Are all BSDs created equally?
I haven't seen this mentioned on the NetBSD mailing lists,
and this may be of interest to some -
there was a talk about security bugs in the various BSDs at the 34th Chaos
Communication Congress:
In summary, many reasons for bugs are shown in many areas of the kernel
(system calls, file systems, network stack, compat layer, ...), and what has
happened after they were made known to the projects.
As a hint, NetBSD still has a number of Security Advisories to publish, it
seems. Anyone wants to help out the security team? :-)
[Tags: 34c3, Security]
|
|
[20170608]
|
g4u 2.6 released
After a five-year period for beta-testing and updating,
I have finally released g4u 2.6. With its origins in 1999,
I'd like to say: Happy 18th Birthday, g4u!
About g4u:
g4u ("ghosting for unix") is a NetBSD-based bootfloppy/CD-ROM that allows easy cloning of PC harddisks to deploy a common setup on a number of PCs using FTP. The floppy/CD offers two functions. The first is to upload the compressed image of a local harddisk to a FTP server, the other is to restore that image via FTP, uncompress it and write it back to disk. Network configuration is fetched via DHCP. As the harddisk is processed as an image, any filesystem and operating system can be deployed using g4u. Easy cloning of local disks as well as partitions is also supported.
The past:
When I started g4u, I had the task to install a number
of lab machines with a dual-boot of Windows NT and NetBSD.
The hype was about Microsoft's "Zero Administration Kit" (ZAK)
then, but that did barely work for the Windows part - file transfers were
slow, depended on the clients' hardware a lot (requiring fiddling with MS
DOS network driver disks), and on the ZAK server the files for
installing happened do disappear for no good reason every now and then.
Not working well, and leaving out NetBSD (and everything elase),
I created g4u. This gave me the (relative) pain of getting
things working once, but with the option to easily add network
drivers as they appeared in NetBSD (and oh they did!), plus allowed
me to install any operating system.
The present:
We've used g4u successfully in our labs then, booting from CDROM.
I also got many donations from public and private instituations
plus comanies from many sectors, indicating that g4u does make a
difference.
In the mean time, the world has changed, and CDROMs aren't used
that much any more. Network boot and USB sticks are today's devices
of choice, cloning of a full disk without knowing its structure
has both advantages but also disadvantages, and g4u's user interface
is still command-line based with not much space for automation.
For storage, FTP servers are nice and fast, but alternatives
like SSH/SFTP, NFS, iSCSI and SMB for remote storage plus local storage
(back to fun with filesystems, anyone? avoiding this was why g4u
was created in the first place!) should be considered these days.
Further aspects include integrity (checksums), confidentiality
(encryption).
This leaves a number of open points to address either by
future releases, or by other products.
The future:
At this point, my time budget for g4u is very limited.
I welcome people to contribute to g4u - g4u is Open Source
for a reason. Feel free to get back to me for any changes
that you want to contribute!
The changes:
Major changes in g4u 2.6 include:
- Make this build with NetBSD-current sources as of 2017-04-17 (shortly before netbsd-8 release branch), binaries were cross-compiled from Mac OS X 10.10
- Many new drivers, bugfixes and improvements from NetBSD-current (see beta1 and beta2 announcements)
- Go back to keeping the disk image inside the kernel as ramdisk, do not load it as separate module. Less error prone, and allows to boot the g4u (NetBSD) kernel from a single file e.g. via PXE (Testing and documentation updates welcome!)
- Actually DO provide the g4u (NetBSD) kernel with the embedded g4u disk image from now on, as separate file, g4u-kernel.gz
- In addition to MD5, add SHA512 checksums
The software:
Please see
the g4u homepage's download section
on how to get and use g4u.
Enjoy!
[Tags: g4u, Releases]
|
|
[20170608]
|
Native Command Queuing - merging and testing
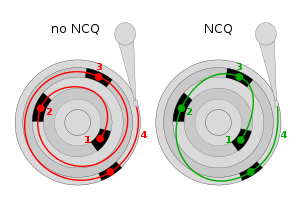 Jaromir Dolecek has worked on NCQ and is looking for
testers in context of merging the development branch
into NetBSD-current.
Jaromir Dolecek has worked on NCQ and is looking for
testers in context of merging the development branch
into NetBSD-current.
What is NCQ? According to
Wikipedia,
``Native Command Queuing (NCQ) is an extension of the Serial ATA protocol allowing hard disk drives to internally optimize the order in which received read and write commands are executed. This can reduce the amount of unnecessary drive head movement, resulting in increased performance (and slightly decreased wear of the drive) for workloads where multiple simultaneous read/write requests are outstanding, most often occurring in server-type applications.''
Jaromir
writes to tech-kern:
``I plan to merge the branch to HEAD very soon, likely over the weekend. Eventual further fixes will be done on HEAD already, including mvsata(4) restabilization, and potential switch of siisata(4) to support NCQ.
The plan is to get this pulled up to netbsd-8 branch soon also, so that it will be part of 8.0.
Status:
- ahci(4) fully working with NCQ (confirmed with qemu, and real hw)
- piixide(4) continues working (no NCQ support of course) (confirmed in qemu)
- siisata(4) continues working (without NCQ still) (confirmed with real hw)
- mvsata(4) not yet confirmed working after changes, mainly due the DMA not really working on Marvell 88SX6042 which I have available - I have same issue as kern/52126
- other ide/sata drivers received mechanical changes, should continue working as before''
Testing and feedback of success or suggestions for improvemenbt
are always welcome - please send your report!
[Tags: ncq, sata, storage]
|
|
[20170521]
|
Support for Controller Area Networks (CAN) in NetBSD
Manuel Bouyer has worked on NetBSD CAN-support, and now he
writes:
``I'd like to merge the bouyer-socketcan branch to HEAD in the next few
days (hopefully early next week, or maybe sunday), unless someone objects
to the idea of a socketcan implementation in NetBSD.
CAN stands for Controller Area Network, a broadcast network used
in automation and automotive fields. For example, the NMEA2000 standard
developped for marine devices uses a CAN network as the link layer.
This is an implementation of the linux socketcan API:
https://www.kernel.org/doc/Documentation/networking/can.txt
you can also see can(4) in the branch.
This adds a new socket family (AF_CAN) and protocol (PF_CAN),
as well as the canconfig(8) utility, used to set timing parameter of
CAN hardware. The branch also includes a driver for the CAN controller
found in the allwinner A20 SoC (I tested it with an Olimex lime2 board,
connected with PIC18-based CAN devices).
There is also the canloop(4) pseudo-device, which allows to use
the socketcan API without CAN hardware.
At this time the CANFD part of the linux socketcan API is not implemented.
Error frames are not implemented either. But I could get the cansend and
canreceive utilities from the canutils package to build and run with minimal
changes. tcpdump(8) can also be used to record frames, which can be
decoded with etherreal.
A review of the code in src/sys/netcan/ is welcome, especially for possible
locking issues.''
What CAN devices would you address with NetBSD? Drop me mail!
[Tags: can, networking]
|
|
[20170505]
|
Announcing NetBSD and the Google Summer of Code Projects 2017
 The NetBSD Project posts that
we are very happy to announce that the selection process in this year's
Summer of Code with its bargaining of slots and what student gets assigned
to which project is over. As a result, the following students will take on
their projects:
The NetBSD Project posts that
we are very happy to announce that the selection process in this year's
Summer of Code with its bargaining of slots and what student gets assigned
to which project is over. As a result, the following students will take on
their projects:
- Leonardo Taccari will work add multi-packages support to pkgsrc.
- Maya Rashish will work on the LFS cleanup.
- Utkarsh Anand will make Anita support multiple virtual machine systems
and more architectures within them to improve testing coverage.
What follows now is a community bonding period until May 30th, followed by a
coding period over the summer (it's Summer of Code, after all :-)
until August 21st, evaluations, code submission and an announcement of the
results on September 6th 2017.
Good luck to all our students and their mentors - we look forward to your
work results, and welcome you to The NetBSD Project!
[Tags: google-soc]
|
|