|
[20161113]
|
Learning more about the NetBSD scheduler (... than I wanted to know)
I've had another chat with Michael on the scheduler issue,
and we agreed that someone should review his proposed patch.
Some interesting things came out from there:
- I learned a bit more about the scheduler from Michael.
With multiple CPUs, each CPU has a queue of processes that
are either "on the CPU" (running) or waiting to be serviced
(run) on that CPU. Those processes count as "migratable"
in runqueue_t.
Every now and then, the system checks all its run queues
to see if a CPU is idle, and can thus "steal" (migrate) processes from
a busy CPU. This is done in
sched_balance().
Such "stealing" (migration) has the positive effect that the
process doesn't have to wait for getting serviced on the CPU
it's currently waiting on. On the other side, migrating the
process has effects on CPU's data and instruction caches,
so switching CPUs shouldn't be taken too easy.
If migration happens, then this should be done from the CPU
with the most processes that are waiting for CPU time.
In this calculation, not only the current number should be
counted in, but a bit of the CPU's history is taken into
account, so processes that just started on a CPU are
not taken away again immediately. This is what is done
with the help of the processes currently migratable
(r_mcount) and also some "historic"
average. This "historic" value is taken from the previous round in
r_avgcount.
More or less weight can be given to this, and it seems
that the current number of migratable processes had too
little weight over all to be considerend.
What happens in effect is that a process is not taken from its
CPU, left waiting there, with another CPU spinning idle.
Which is exactly what I saw
in the first place.
- What I also learned from Michael was that there are a number of
sysctl variables that can be used to influence the scheduler.
Those are available under the "kern.sched" sysctl-tree:
% sysctl -d kern.sched
kern.sched.cacheht_time: Cache hotness time (in ticks)
kern.sched.balance_period: Balance period (in ticks)
kern.sched.min_catch: Minimal count of threads for catching
kern.sched.timesoftints: Track CPU time for soft interrupts
kern.sched.kpreempt_pri: Minimum priority to trigger kernel preemption
kern.sched.upreempt_pri: Minimum priority to trigger user preemption
kern.sched.rtts: Round-robin time quantum (in milliseconds)
kern.sched.pri_min: Minimal POSIX real-time priority
kern.sched.pri_max: Maximal POSIX real-time priority
The above text shows that much more can be written about
the scheduler and its whereabouts, but this remains to be done
by someone else (volunteers welcome!).
- Now, while digging into this, I also learned that I'm not the first
to discover this issue, and there is already another PR on this.
I have opened PR
kern/51615
but there is also
kern/43561. Funny enough, the solution proposed there is about the same,
though with a slightly different implementation. Still, *2 and
<<1 are the same as are /2 and >>1, so no change there.
And renaming variables for fun doesn't count anyways. ;)
Last but not least, it's worth noting that this whole
issue is not Xen-specific.
So, with this in mind, I went to do a bit of testing.
I had already tested running concurrent, long-running processes
that did use up all the CPU they got, and the test was good.
To test a different load on the system,
I've started a "build.sh -j8" on a (VMware Fusion) VM with 4 CPUs on a
Macbook Pro, and it nearly brought the machine to a halt - What I saw was
lots of idle time on all CPUs though. I aborted the exercise to get some
CPU cycles for me back. I blame the VM handling here, not the guest
operating system.
I restarted the exercise with 2 CPUs in the same VM, and there I saw load
distribution on both CPUs (not much wonder with -j8), but there was also
quite some idle times in the 'make clean / install' phases that I'm not
sure is normal. During the actual build phases I wasn't able to see idle
time, though the system spent quite some time in the kernel (system).
Example top(1) output:
load averages: 9.01, 8.60, 7.15; up 0+01:24:11 01:19:33
67 processes: 7 runnable, 58 sleeping, 2 on CPU
CPU0 states: 0.0% user, 55.4% nice, 44.6% system, 0.0% interrupt, 0.0% idle
CPU1 states: 0.0% user, 69.3% nice, 30.7% system, 0.0% interrupt, 0.0% idle
Memory: 311M Act, 99M Inact, 6736K Wired, 23M Exec, 322M File, 395M Free
Swap: 1536M Total, 21M Used, 1516M Free
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
27028 feyrer 20 5 62M 27M CPU/1 0:00 9.74% 0.93% cc1
728 feyrer 85 0 78M 3808K select/1 1:03 0.73% 0.73% sshd
23274 feyrer 21 5 36M 14M RUN/0 0:00 10.00% 0.49% cc1
21634 feyrer 20 5 44M 20M RUN/0 0:00 7.00% 0.34% cc1
24697 feyrer 77 5 7988K 2480K select/1 0:00 0.31% 0.15% nbmake
24964 feyrer 74 5 11M 5496K select/1 0:00 0.44% 0.15% nbmake
18221 feyrer 21 5 49M 15M RUN/0 0:00 2.00% 0.10% cc1
14513 feyrer 20 5 43M 16M RUN/0 0:00 2.00% 0.10% cc1
518 feyrer 43 0 15M 1764K CPU/0 0:02 0.00% 0.00% top
20842 feyrer 21 5 6992K 340K RUN/0 0:00 0.00% 0.00% x86_64--netb
16215 feyrer 21 5 28M 172K RUN/0 0:00 0.00% 0.00% cc1
8922 feyrer 20 5 51M 14M RUN/0 0:00 0.00% 0.00% cc1
All in all, I'd say the patch is a good step forward from the current
situation, which does not properly distribute pure CPU hogs, at all.
[Tags: scheduler, smp]
|
|
[20161105]
|
NetBSD 7.0/xen scheduling mystery, and how to fix it with processor sets
Today I had a need to do some number crunching using a home-brewn
C program. In order to do some manual load balancing, I was firing
up some Amazon AWS instances (which is Xen) with NetBSD 7.0.
In this case, the system was assigned two CPUs, from dmesg:
# dmesg | grep cpu
vcpu0 at hypervisor0: Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz, id 0x306e4
vcpu1 at hypervisor0: Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz, id 0x306e4
I started two instances of my program, with the intent to
have each one use one CPU. Which is not what
happened! Here is what I observed, and how I fixed things for now.
I was looking at top(1) to see that everything was running fine,
and noticed funny WCPU and CPU values:
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
2791 root 25 0 8816K 964K RUN/0 16:10 54.20% 54.20% myprog
2845 root 26 0 8816K 964K RUN/0 17:10 47.90% 47.90% myprog
I expected something like WCPU and CPU being around 100%, assuming
that each process was bound to its own CPU. The values I actually
saw (and listed above) suggested that both programs were fighting
for the same CPU. Huh?!
top's CPU state shows:
load averages: 2.15, 2.07, 1.82; up 0+00:45:19 18:00:55
27 processes: 2 runnable, 23 sleeping, 2 on CPU
CPU states: 50.0% user, 0.0% nice, 0.0% system, 0.0% interrupt, 50.0% idle
Memory: 119M Act, 7940K Exec, 101M File, 3546M Free
Which is not too useful. Typing "1" in top(1) lists the actual per-CPU usage
instead:
load averages: 2.14, 2.08, 1.83; up 0+00:45:56 18:01:32
27 processes: 4 runnable, 21 sleeping, 2 on CPU
CPU0 states: 100% user, 0.0% nice, 0.0% system, 0.0% interrupt, 0.0% idle
CPU1 states: 0.0% user, 0.0% nice, 0.0% system, 0.0% interrupt, 100% idle
Memory: 119M Act, 7940K Exec, 101M File, 3546M Free
This confirmed my suspicion that both processes were bound to one
CPU, and that the other one was idling. Bad! But how to fix?
One option is to kick your operating system out of the window,
but I still like NetBSD, so here's another solution:
NetBSD allows to create "processor sets",
assign CPU(s) to them and then assign processes to
the processor sets. Let's have a look!
Processor sets are manipulated using the
psrset(8) utility. By default all CPUs are in the same (system) processor set:
# psrset
system processor set 0: processor(s) 0 1
First step is to create a new processor set:
# psrset -c
1
# psrset
system processor set 0: processor(s) 0 1
user processor set 1: empty
Next, assign one CPU to the new set:
# psrset -a 1 1
# psrset
system processor set 0: processor(s) 0
user processor set 1: processor(s) 1
Last, find out what the process IDs of my two (running) processes are,
and assign them to the two processor sets:
# ps -u
USER PID %CPU %MEM VSZ RSS TTY STAT STARTED TIME COMMAND
root 2791 52.0 0.0 8816 964 pts/4 R+ 5:28PM 22:57.80 myprog
root 2845 50.0 0.0 8816 964 pts/2 R+ 5:26PM 23:33.97 myprog
#
# psrset -b 0 2791
# psrset -b 1 2845
Note that this was done with the two processes running,
there is no need to stop and restart them!
The effect of the commands is imediate, as can be seen in top(1):
load averages: 2.02, 2.05, 1.94; up 0+00:59:32 18:15:08
27 processes: 1 runnable, 24 sleeping, 2 on CPU
CPU0 states: 100% user, 0.0% nice, 0.0% system, 0.0% interrupt, 0.0% idle
CPU1 states: 100% user, 0.0% nice, 0.0% system, 0.0% interrupt, 0.0% idle
Memory: 119M Act, 7940K Exec, 101M File, 3546M Free
Swap:
PID USERNAME PRI NICE SIZE RES STATE TIME WCPU CPU COMMAND
2845 root 25 0 8816K 964K CPU/1 26:14 100% 100% myprog
2791 root 25 0 8816K 964K RUN/0 25:40 100% 100% myprog
Things are as expected now, with each program being bound to its
own CPU.
Now why this didn't happen by default is left as an exercise to the reader.
Hints that may help:
# uname -a
NetBSD foo.eu-west-1.compute.internal 7.0 NetBSD 7.0 (XEN3_DOMU.201509250726Z) amd64
# dmesg
...
hypervisor0 at mainbus0: Xen version 4.2.amazon
VIRQ_DEBUG interrupt using event channel 3
vcpu0 at hypervisor0: Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz, id 0x306e4
vcpu1 at hypervisor0: Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz, id 0x306e4
AWS Instance type: c3.large
AMI ID: NetBSD-x86_64-7.0-201511211930Z-20151121-1142 (ami-ac983ddf)
[Tags: amazon, aws, psrset, scheduler, smp, xen]
|
|
[20140312]
|
NetBSD/arm news: netwalker, SMP, DTrace
In the past few weeks, several news items
regarding NetBSD's port to ARM platforms came up:
-
 The port to the NETWALKER (Cortex-A8) platform works as
confirmed by Jun Ebihara,
including instructions on how to set things up and
dmesg output.
The port to the NETWALKER (Cortex-A8) platform works as
confirmed by Jun Ebihara,
including instructions on how to set things up and
dmesg output.
- Ryota Ozaki is working on porting DTrace to ARM
- Matt Thomas is making the ARM port ready to use
multiple CPUs, see his posting,
which shows a list of processes and their associated CPU.
[Tags: arm, dmesg, dtrace, netwalker, smp]
|
|
[20120603]
|
SMP-ready USB stack on its way for NetBSD - testers welcome!
Matt Green has picked up Jared McNeill's work on
making the NetBSD USB stack SMP-ready.
Besides the USB framework itself, this is also relevant
for all the various drivers that can attach to USB -
starting form audio drivers over SCSI to serial (ucom) drivers.
While the work is far from complete, it is in a shape where
users are welcome to start testing, and where developers
are also welcome to help in converting more drivers!
Please join in and help test the code, and send your
feedback to the lists. If no serious issues come up,
the code will be merged within a week.
See
Matt's posting to tech-kern
for more details, inclusing diffs and links for
amd64 and i386 GENERIC (+usbmp) kernels.
Further information on the state of the code - what is and what is not
converted yet - can be found
in the TODO.usbmp file.
[Tags: smp, usb]
|
|
[20120307]
|
NetBSD/xen available for Multi-Processor machines
Manuel Bouyer
announces
that NetBSD/xen is now available for Multi-Processor machines.
Citing from the release announcement:
``The NetBSD Foundation is pleased to announce completion of
Multiprocessing Support for the port of its Open Source Operating
System to the Xen hypervisor.
The NetBSD Fundation started the Xen MP project 8 month ago; the goal
was to add SMP support to NetBSD/Xen domU kernels. This project has
officially completed, and after a few bug fixes in the pmap(9) code it
is now considered stable on both i386 and amd64. NetBSD 6.0 will ship
with option MULTIPROCESSOR enabled by default for Xen domU kernels.
The availability of Xen MP support in NetBSD allows to run the NetBSD
Open Source Operating Systems on a range of available infrastructure
providers' systems. Amazon's Web Services with their Elastic Cloud
Computing is a prominent examples here.
Xen is a virtualization software that enables several independent
operating system instances ("domains") to run concurrently on the same
computer hardware. The hardware is managed by the first domain (dom0),
and further guest/user domains (domU) are spawned and managed by dom0.
Operating systems available for running as dom0 and domU guests
include Microsoft Windows, Solaris and Linux besides NetBSD.
NetBSD is a free, fast, secure, and highly portable Unix-like Open
Source operating system. It is available for a wide range of
platforms, from large-scale servers and powerful desktop systems to
handheld and embedded devices. Its clean design and advanced features
make it excellent for use in both production and research
environments, and the source code is freely available under a
business-friendly license. NetBSD is developed and supported by a
large and vivid international community. Many applications are readily
available through pkgsrc, the NetBSD Packages Collection.
NetBSD has been available for the Xen hypervisor since Xen 1 and
NetBSD 2.0, released in 2004 , but until now only a single
processor was supported in each NetBSD/xen domain.''
[Tags: amazon, ec2, smp, xen]
|
|
[20090504]
|
Article: Thread scheduling and related interfaces in NetBSD 5.0
Mindaugas Rasiukevicius has worked in the SMP corner of the
NetBSD kernel in the past few months, and he has written
an article that introduces the work done by him and others,
see
his posting
for a bit more information, or
his article directly.
The article introduces real-time scheduling and the scheduling
classes found in NetBSD 5.0, and gives an estimate on the
response timeframe that can be expected for real-time applications.
Setting scheduling policy and priority from a userland
application is shown next, and programming examples for
thread affinity, dynamic CPU sets and processor sets are
shown. Besires C APIs, there are also a number or new commands
in NetBSD 5.0 that can be used to control things from the command
line, e.g. to define scheduling behaviour and manipulate
processor sets. My favourite gem is the CPU used in the
cpuctl(8) example, which is identified as "AMD Engineering Sample". :-)
[Tags: Articles, dmesg, posix, pthread, smp]
|
|
[20090112]
|
More kernel tuning in progress
Andrew Doran is at it again, and he has proposed a number
of patches to further improve NetBSD's performance in
various areas:
- Optimization for exec by using a cached copy of
the file's exec header, and reducing locking-overhead by keeping
locks instead of freeing them and the immediately re-locking them.
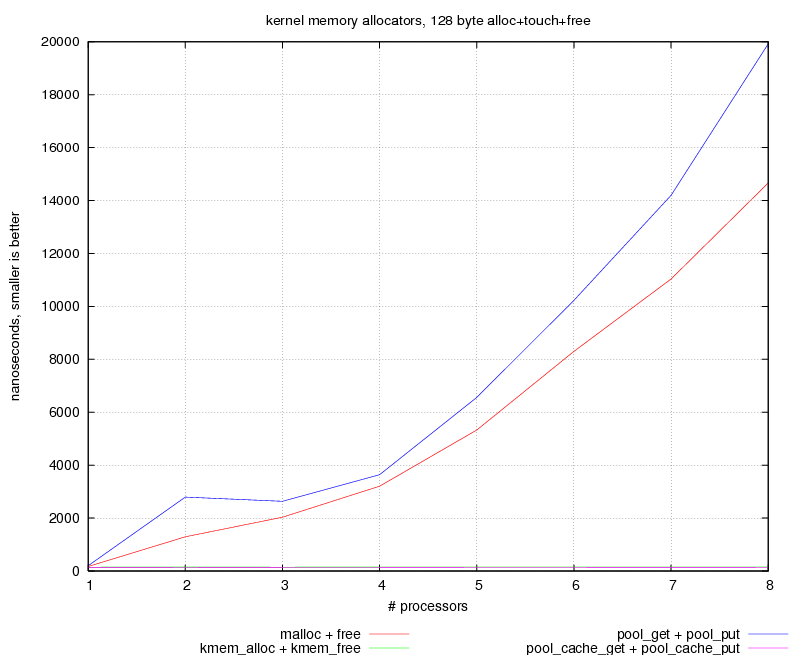
- The NetBSD kernel offers a few internal interfaces for allocating
memory, depending on use of the memory, duration of use, size,
etc. For some of the proper SMP-handling is important, and thus
the number of CPUs has an impact on their performance.
By adding caching,
this can be mitigated to get linear behaviour, independent
from the number of CPUs:
- The openat() and fstatat() system calls are not available in NetBSD
yet, but other systems offer them, standards are about to pick
them up, and ZFS assumes their presence. The system calls offer a way
to way to specify a different directory to which relative paths
are relative to, other than ".", by passing a file descriptor for
that directory. Now there is a patch to
add openat() and fstatat() to NetBSD.
- In theory, pipes are just a special case of (host-local) sockets,
but it makes sense to keep a separate implementation for reasons of
speed optimizations. NetBSD has the "PIPE_SOCKETPAIR" kernel option
to force use of the socket code for pipes in order to reduce
the memory footprint, but
benchmarks reflect the performace hit.
In order to improve the the situation,
a number of improvements are under way,
including better cache utilization and SMP-compliant memory
allocation over homegrown memory management.
- Improved performance of exit(2)
- this is important in environments with many short-running processes
(think httpd, inetd).
- As a final step, freeing entries in the translation
lookaside buffer (TLB) of the x86 (i386, amd64, xen) memory management unit
AKA TLB shootdown
were sped up
to a point where TLB shootdown interrupts are 50% down during a system
rebuild on an 8-cpu machine, and several million(!) calls page
invalidation were optimized away, resulting in a 1% speed increase
on the overall build.
- A partial(!) port of Sun's ZFS is also
made available. It's not at the state
where it can be used, but should be a good starting point
for an experienced kernel hacker to continue working.
See Andrew's mail to tech-kern
for further directions.
[Tags: openat, smp, zfs]
|
|
[20080612]
|
More kernel works: audio, benchmarks, modules
In the past few weeks, Andrew Doran has made another bunch of
changes to NetBSD's kernel area, including interrupts in NetBSD's
audio framework, benchmarks of the system, and the handling of
kernel modules.
SMP & audio:
One area that hasn't been changed
for moving towards fine-grained kernel locking was NetBSD's audio
subsystem. As audio recording and playback is mostly done via
interrupts, and as latency in those is critical, the audio
subsystem was moved to the new interrupt handling system.
The work can be found on the ad-audiomp branch, more information
is available in Andrew's posting about the MP safe
audio framework and drivers.
Benchmarking:
Changing a system from inside out is a huge technical task.
On the way, performance measurements and tuning are needed to
make sure that the previous performance is still achieved while
getting better performance in the desired development area.
As a result,
benchmarks results from Sun's
libmicro
benchmark suite
were
posted, which allow comparison not only against Linux and FreeBSD, but
also between NetBSD-current and NetBSD 4.0, in order to identify if any bad
effects were added. All performance tests were made on a machine with 8
CPUs, and the areas tested cover "small" (micro) areas like various system calls. Of course this doesn't lead to a 1:1 statement on how
the systems will perform in a real-life scenario like e.g. in a
database performance test, but it still help identifying
problems and gives better hints where tuning can be done.
Another benchmark that was also made in that regard comes
from Gregory McGarry, who has published
performance measurements previously.
This time, Gregory
has run the lmbench 3.0 benchmark on
recent NetBSD and FreeBSD systems as well as a number of previous
NetBSD releases - useful for identifying performance degradation, too!
 One other benchmark on dispatch latency
run was made by Andrew Doran: on a machine
that was (CPU-wise) loaded by some compile jobs, he started a
two threads on a CPU that wasn't distracted by device interrupts,
and measured how fast the scheduler reacted when one thread
woke up the other one. The resulting graph
shows that the scheduler handles the majority of requests in less than
10us - good enough for some realtime applications?
One other benchmark on dispatch latency
run was made by Andrew Doran: on a machine
that was (CPU-wise) loaded by some compile jobs, he started a
two threads on a CPU that wasn't distracted by device interrupts,
and measured how fast the scheduler reacted when one thread
woke up the other one. The resulting graph
shows that the scheduler handles the majority of requests in less than
10us - good enough for some realtime applications?
Kernel modules
are another area that's under heavy change right now, and after
recent changes to load modules from the bootloader and the kernel,
the kernel build process was now changed
so that pre-built kernel
modules can be linked into a new kernel binary, resulting in a
non-modular kernel. Eventually, this could mean that
src/sys is built into separate modules, and that the (many) existing
kernels that are present for each individual platform -- GENERIC,
INSTALL is already gone, ALL, etc. etc. -- can be simply linked from
pre-compiled modules, without recompiling things over again for each
kernel. Of course the overal goal here is to speed up the system (and
kernel!) build time, while maintaining maximum flexibility between
modules and non-modular kernels.
With the progress in kernel modules, it is a question of time
when the new kernel module handling supercedes the existing
loadable kernel modules to such an extent that the latter will
be completely removed from the system -- at least the
latter
was alredy proposed, but I'd prefer to
see some documentation of the new system first. We'll see
what comes first! (Documentation writers are always welcome! :-)
[Tags: benchmark, kernel, smp]
|
|
[20080409]
|
SMP on OpenFirmware based PowerPC machines in-tree
There's more to SMP than just Intel- and -compatible machines.
PowerPC-hackers Tim Rightnour and Matt Thomas have added support for SMP on
OpenFirmware based PowerPC machines, i.e. the
NetBSD/ofppc port.
The support is already committed to the NetBSD-current source tree,
and Tim has posted
the dmesg output of a 4-CPU machine, an
IBM 7044-270.
He also notes that this is the first PowerPC machine with
four processors to ever run NetBSD.
[Tags: dmesg, ofppc, smp]
|
|
[20080409]
|
How to get world-class SMP performance with NetBSD, by ad and rmind
Andew Doran is currently employed by The NetBSD Foundation to change
NetBSD's SMP implementation from big-lock to fine-grained kernel locking.
With hin, Mindaugas Rasiukevicius has done a lot of work on NetBSD's
scheduler, and Yamamoto Takashi has added a fair share of further
infrastructure work in the kernel.
I've asked them about their progress
in the past months, and the following points give a rough idea on what
was achieved so far, and what can still be expected.
The story so far.
Andrew Doran writes: ``
The kernel synchronization model has been completely revamped since NetBSD
4.0, with the goal of making NetBSD a fully multithreaded, multiprocessor
system with complete support for soft real-time applications.
Through NetBSD 4.0, the kernel used spinlocks and a per-CPU interrupt
priority level (the spl(9) system) to provide mutual exclusion. These
mechanisms did not lend themselves well to a multiprocessor environment
supporting kernel preemption. Rules governing their use had been built up
over many years of development, making them difficult to understand and use
well. The use of thread based (lock) synchronization was limited and the
available synchronization primitive (lockmgr) was inefficient and slow to
execute.
In development branch that will becomple NetBSD 5.0, a new rich set of
synchronization primitives and software tools have been developed to ease
writing multithreaded kernel code that executes efficiently and safely on
SMP systems. Some of these are:
- Thread-base adaptive mutexes. These are lightweight, exclusive locks that
use threads as the focus of synchronization activity. Adaptive mutexes
typically behave like spinlock, but under specific conditions an attempt
to acquire an already held adaptive mutex may cause the acquring thread to
sleep. Sleep activity occurs rarely. Busy-waiting is typically more
efficient because mutex hold times are most often short. In contrast to
pure spinlocks, a thread holding an adaptive mutex may be preempted in the
kernel, which can allow for reduced latency where soft real-time
application are in use on the system.
- Reader/writer locks. These are lightweight shared/exclusive locks that
again use threads as the focus of synchronization activity. Their area of
use is limited, most of it being in the file system code.
- CPU based spin mutexes, used mainly within the scheduler, device drivers
and device driver support code. Pure spin mutexes are used when it is not
safe, or impossible for, a thread to use a synchronization method that
could block such as an adaptive mutex.
- Priority inheritance, implemented in support of soft real-time applications.
Where a high priority thread is blocked waiting for a resource held by a
lower priority thread, the kernel can temporarily "lend" a high priority
level to the lower priority thread. This helps to ensure that the lower
priority thread does no unduly obstruct the progress of the higher
priority thread.
- Atomic operations. A full set of atomic operations implementing arithmetic
and memory barrier operations has been provided. The atomic operations are
available both in the kernel and to user applications, via the C library.
- Generic cross calls: a facility that allows one CPU or thread to easily
make an arbitrary function call on any other CPUs in the system.
- The interrupt priority level interfaces (spl(9)) have long been used to
block interrupts on a CPU-local basis. These interfaces have been
simplified and streamlined to allow for code and algorithms that make use
of low cost CPU-local synchronization. In addition, APIs are provided that
allow detection of kernel preemption and allow the programmer to
temporarily disable preemption across critical sections of code that
cannot tolerate any interruption.
- "percpu" memory allocator: a simple memory allocator that provides
arbitrary amounts of keyed storage. Allocations are replicated across all
CPUs in the system and each CPU has its own private instance of any
allocated object. Together, the cross call facility, atomic operations,
spl(9) interfaces and percpu allocator make it easy to build lightweight,
lock-free algorithms.
- Lockless memory allocators: the standard kernel memory allocators have been
augmented with per-CPU caches which signficantly avoid costly synchronization
overhead typically associated with allocation of memory on a multiprocessor
system. ''
Mindaugas adds a few more items: ``
- New thread scheduler, named M2: it reduces the lock contention, and
increases the thread affinity to avoid cache thrashing - this essentially
improves the performance on SMP systems. M2 implements time-sharing class,
and POSIX real-time extensions, used by soft real-time applications.
- Processor sets and affinity API provides possibility to bind the processes
or threads to the specific CPU or group of CPUs. This allows applications
to achieve better concurrency, CPU utilization, avoid cache thrashing and
thus improve the performance on SMP systems.
''
The Future.
Besides those achievements, there is more development work ongoing,
and a number of items were presented for review and comment the
past week, which will have further impact on NetBSD's performace
on multicore and SMP machines:
- A scheduler is responsible for distributing workdload on CPUs,
and besides the 4BSD scheduler, a more modern "M2"-scheduler was
recently added to NetBSD, see above. Parts of that scheduler were
now suggested to be included in the general scheduling framework.
That way, the 4BSD scheduler gets processor affinity (so threads /
processes keep stuck to a single CPU and thus reduce cache misses
when migrating between CPUs/cores).
 With other changes surrounding this, NetBSD-current beats
FreeBSD 7.0 and all earlier NetBSD releases when running build.sh
(i.e. compiling the whole system) on a 8-core machine. In the image,
small values mean less time for the build, and are thus good.
I find the results impressive.
For more information, see
Andrew's posting to tech-kern.
With other changes surrounding this, NetBSD-current beats
FreeBSD 7.0 and all earlier NetBSD releases when running build.sh
(i.e. compiling the whole system) on a 8-core machine. In the image,
small values mean less time for the build, and are thus good.
I find the results impressive.
For more information, see
Andrew's posting to tech-kern.
- Reader/writer locks
are a locking primitive used to allow multiple readers, but to
block them if one or more processes want to write to a ressource.
Those locks are used in the NetBSD kernel, see the
rwlock(9) manpage.
In order to further optimize the performance of the
rwlock primitives, a few optimizations were
suggested by Andrew Doran
which reduces the build time on an 8-cpu machine by 4%:
``There is less idle time during the build because the windows where
a rwlock can be held but the owner is not running is reduced''.
- Another optimization was
suggested
which cuts down another 5% of the time for a complete system build
via build.sh on an 8-core machine, this time by replacing a linear
list of locks in the namei cache with a hash table for the locks.
The namei cache helps to speed up translations from a path name
to the corresponding vnodes, see
namei(9).
A call for participation: Benchmark!
I think this is a very long list of changes, which will all be available
in the next major release of NetBSD. Starting now, it would be interesting
to measure and estimate the performance of NetBSD in comparison to
other operating systems that emphasize SMP (but still keep performance
a goal on uniprocessor machines) -- FreeBSD, Linux and Solaris/x86 come
to mind. Possible benchmarks could include simple Bytebench, dhrystone
and Bonnie benchmarks over more complex ones like postmark and database
and webserver benchmarks. If anyone has numbers and/or graphs,
please post them to the tech-perform@NetBSD.org mailing list!
[Tags: smp]
|
|
Tags: ,
2bsd,
34c3,
3com,
501c3,
64bit,
acl,
acls,
acm,
acorn,
acpi,
acpitz,
adobe,
adsense,
Advocacy,
advocacy,
advogato,
aes,
afs,
aiglx,
aio,
airport,
alereon,
alex,
alix,
alpha,
altq,
am64t,
amazon,
amd64,
anatomy,
ansible,
apache,
apm,
apple,
arkeia,
arla,
arm,
art,
Article,
Articles,
ascii,
asiabsdcon,
aslr,
asterisk,
asus,
atf,
ath,
atheros,
atmel,
audio,
audiocodes,
autoconf,
avocent,
avr32,
aws,
axigen,
azure,
backup,
balloon,
banners,
basename,
bash,
bc,
beaglebone,
benchmark,
bigip,
bind,
blackmouse,
bldgblog,
blog,
blogs,
blosxom,
bluetooth,
board,
bonjour,
books,
boot,
boot-z,
bootprops,
bozohttpd,
bs2000,
bsd,
bsdca,
bsdcan,
bsdcertification,
bsdcg,
bsdforen,
bsdfreak,
bsdmac,
bsdmagazine,
bsdnexus,
bsdnow,
bsdstats,
bsdtalk,
bsdtracker,
bug,
build.sh,
busybox,
buttons,
bzip,
c-jump,
c99,
cafepress,
calendar,
callweaver,
camera,
can,
candy,
capabilities,
card,
carp,
cars,
cauldron,
ccc,
ccd,
cd,
cddl,
cdrom,
cdrtools,
cebit,
centrino,
cephes,
cert,
certification,
cfs,
cgd,
cgf,
checkpointing,
china,
christos,
cisco,
cloud,
clt,
cobalt,
coccinelle,
codian,
colossus,
common-criteria,
community,
compat,
compiz,
compsci,
concept04,
config,
console,
contest,
copyright,
core,
cortina,
coverity,
cpu,
cradlepoint,
cray,
crosscompile,
crunchgen,
cryptography,
csh,
cu,
cuneiform,
curses,
curtain,
cuwin,
cvs,
cvs-digest,
cvsup,
cygwin,
daemon,
daemonforums,
daimer,
danger,
darwin,
data,
date,
dd,
debian,
debugging,
dell,
desktop,
devd,
devfs,
devotionalia,
df,
dfd_keeper,
dhcp,
dhcpcd,
dhcpd,
dhs,
diezeit,
digest,
digests,
dilbert,
dirhash,
disklabel,
distcc,
dmesg,
Docs,
Documentation,
donations,
draco,
dracopkg,
dragonflybsd,
dreamcast,
dri,
driver,
drivers,
drm,
dsl,
dst,
dtrace,
dvb,
ec2,
eclipse,
eeepc,
eeepca,
ehci,
ehsm,
eifel,
elf,
em64t,
Embedded,
embedded,
emips,
emulate,
encoding,
envsys,
eol,
espresso,
etcupdate,
etherip,
euca2ools,
eucalyptus,
eurobsdcon,
eurosys,
Events,
exascale,
ext3,
f5,
facebook,
falken,
fan,
faq,
fatbinary,
features,
fefe,
ffs,
filesystem,
fileysstem,
firefox,
firewire,
fireworks,
flag,
flash,
flashsucks,
flickr,
flyer,
fmslabs,
force10,
fortunes,
fosdem,
fpga,
freebsd,
freedarwin,
freescale,
freex,
freshbsd,
friendlyAam,
friendlyarm,
fritzbox,
froscamp,
fsck,
fss,
fstat,
ftp,
ftpd,
fujitsu,
fun,
fundraising,
funds,
funny,
fuse,
fusion,
g4u,
g5,
galaxy,
games,
gcc,
gdb,
gentoo,
geode,
getty,
gimstix,
git,
gnome,
google,
google-soc,
googlecomputeengine,
gpio,
gpl,
gprs,
gracetech,
gre,
groff,
groupwise,
growfs,
grub,
gumstix,
guug,
gzip,
hackathon,
hackbench,
hal,
hanoi,
happabsd,
Hardware,
hardware,
haze,
hdaudio,
heat,
heimdal,
hf6to4,
hfblog,
hfs,
history,
hosting,
hotplug,
hp,
hp700,
hpcarm,
hpcsh,
hpux,
html,
httpd,
hubertf,
hurd,
i18n,
i386,
i386pkg,
ia64,
ian,
ibm,
ids,
ieee,
ifwatchd,
igd,
iij,
image,
images,
imx233,
imx7,
information,
init,
initrd,
install,
intel,
interix,
internet2,
interview,
interviews,
io,
ioccc,
iostat,
ipbt,
ipfilter,
ipmi,
ipplug,
ipsec,
ipv6,
irbsd,
irc,
irix,
iscsi,
isdn,
iso,
isp,
itojun,
jail,
jails,
japanese,
java,
javascript,
jetson,
jibbed,
jihbed,
jobs,
jokes,
journaling,
kame,
kauth,
kde,
kerberos,
kergis,
kernel,
keyboardcolemak,
kirkwood,
kitt,
kmod,
kolab,
kvm,
kylin,
l10n,
landisk,
laptop,
laptops,
law,
ld.so,
ldap,
lehmanns,
lenovo,
lfs,
libc,
license,
licensing,
linkedin,
links,
linksys,
linux,
linuxtag,
live-cd,
lkm,
localtime,
locate.updatedb,
logfile,
logging,
logo,
logos,
lom,
lte,
lvm,
m68k,
macmini,
macppc,
macromedia,
magicmouse,
mahesha,
mail,
makefs,
malo,
mame,
manpages,
marvell,
matlab,
maus,
max3232,
mbr95,
mbuf,
mca,
mdns,
mediant,
mediapack,
meetbsd,
mercedesbenz,
mercurial,
mesh,
meshcube,
mfs,
mhonarc,
microkernel,
microsoft,
midi,
mini2440,
miniroot,
minix,
mips,
mirbsd,
missile,
mit,
mixer,
mobile-ip,
modula3,
modules,
money,
mouse,
mp3,
mpls,
mprotect,
mtftp,
mult,
multics,
multilib,
multimedia,
music,
mysql,
named,
nas,
nasa,
nat,
ncode,
ncq,
ndis,
nec,
nemo,
neo1973,
netbook,
netboot,
netbsd,
netbsd.se,
nethack,
nethence,
netksb,
netstat,
netwalker,
networking,
neutrino,
nforce,
nfs,
nis,
npf,
npwr,
nroff,
nslu2,
nspluginwrapper,
ntfs-3f,
ntp,
nullfs,
numa,
nvi,
nvidia,
nycbsdcon,
office,
ofppc,
ohloh,
olimex,
olinuxino,
olpc,
onetbsd,
openat,
openbgpd,
openblocks,
openbsd,
opencrypto,
opendarwin,
opengrok,
openmoko,
openoffice,
openpam,
openrisk,
opensolaris,
openssl,
or1k,
oracle,
oreilly,
oscon,
osf1,
osjb,
paas,
packages,
pad,
pae,
pam,
pan,
panasonic,
parallels,
pascal,
patch,
patents,
pax,
paypal,
pc532,
pc98,
pcc,
pci,
pdf,
pegasos,
penguin,
performance,
pexpect,
pf,
pfsync,
pgx32,
php,
pie,
pike,
pinderkent,
pkg_install,
pkg_select,
pkgin,
pkglint,
pkgmanager,
pkgsrc,
pkgsrc.se,
pkgsrcCon,
pkgsrccon,
Platforms,
plathome,
pleiades,
pocketsan,
podcast,
pofacs,
politics,
polls,
polybsd,
portability,
posix,
postinstall,
power3,
powernow,
powerpc,
powerpf,
pppoe,
precedence,
preemption,
prep,
presentations,
prezi,
Products,
products,
proplib,
protectdrive,
proxy,
ps,
ps3,
psp,
psrset,
pthread,
ptp,
ptyfs,
Publications,
puffs,
puredarwin,
pxe,
qemu,
qnx,
qos,
qt,
quality-management,
quine,
quote,
quotes,
r-project,
ra5370,
radio,
radiotap,
raid,
raidframe,
rants,
raptor,
raq,
raspberrypi,
rc.d,
readahead,
realtime,
record,
refuse,
reiserfs,
Release,
releases,
Releases,
releng,
reports,
resize,
restore,
ricoh,
rijndael,
rip,
riscos,
rng,
roadmap,
robopkg,
robot,
robots,
roff,
rootserver,
rotfl,
rox,
rs323,
rs6k,
rss,
ruby,
rump,
rzip,
sa,
safenet,
san,
sata,
savin,
sbsd,
scampi,
scheduler,
scheduling,
schmonz,
sco,
screen,
script,
sdf,
sdtemp,
secmodel,
security,
Security,
sed,
segvguard,
seil,
sendmail,
serial,
serveraptor,
sfu,
sge,
sgi,
sgimips,
sh,
sha2,
shark,
sharp,
shisa,
shutdown,
sidekick,
size,
slackware,
slashdot,
slides,
slit,
smbus,
smp,
sockstat,
soekris,
softdep,
softlayer,
software,
solaris,
sony,
sound,
source,
source-changes,
spanish,
sparc,
sparc64,
spider,
spreadshirt,
spz,
squid,
ssh,
sshfs,
ssp,
statistics,
stereostream,
stickers,
storage,
stty,
studybsd,
subfile,
sudbury,
sudo,
summit,
sun,
sun2,
sun3,
sunfire,
sunpci,
support,
sus,
suse,
sushi,
susv3,
svn,
swcrypto,
symlinks,
sysbench,
sysctl,
sysinst,
sysjail,
syslog,
syspkg,
systat,
systrace,
sysupdate,
t-shirt,
tabs,
talks,
tanenbaum,
tape,
tcp,
tcp/ip,
tcpdrop,
tcpmux,
tcsh,
teamasa,
tegra,
teredo,
termcap,
terminfo,
testdrive,
testing,
tetris,
tex,
TeXlive,
thecus,
theopengroup,
thin-client,
thinkgeek,
thorpej,
threads,
time,
time_t,
timecounters,
tip,
tk1,
tme,
tmp,
tmpfs,
tnf,
toaster,
todo,
toolchain,
top,
torvalds,
toshiba,
touchpanel,
training,
translation,
tso,
tty,
ttyrec,
tulip,
tun,
tuning,
uboot,
ucom,
udf,
ufs,
ukfs,
ums,
unetbootin,
unicos,
unix,
updating,
upnp,
uptime,
usb,
usenix,
useradd,
userconf,
userfriendly,
usermode,
usl,
utc,
utf8,
uucp,
uvc,
uvm,
valgrind,
vax,
vcfe,
vcr,
veriexec,
vesa,
video,
videos,
virtex,
virtualization,
vm,
vmware,
vnd,
vobb,
voip,
voltalinux,
vpn,
vpnc,
vulab,
w-zero3,
wallpaper,
wapbl,
wargames,
wasabi,
webcam,
webfwlog,
wedges,
wgt624v3,
wiki,
willcom,
wimax,
window,
windows,
winmodem,
wireless,
wizd,
wlan,
wordle,
wpa,
wscons,
wstablet,
X,
x.org,
x11,
x2apic,
xbox,
xcast,
xen,
Xen,
xfree,
xfs,
xgalaxy,
xilinx,
xkcd,
xlockmore,
xmms,
xmp,
xorg,
xscale,
youos,
youtube,
zaurus,
zdump,
zfs,
zlib
'nuff.
Grab the RSS-feed,
index,
or go back to my regular NetBSD page
Disclaimer: All opinion expressed here is purely my own.
No responsibility is taken for anything.